Сравнение OpenCL с CUDA, GLSL и OpenMP

На хабре уже рассказали о том, что такое OpenCL и для чего он нужен, но этот стандарт сравнительно новый, поэтому интересно как соотносится производительность программ на нём с другими решениями.
В этом топике приведено сравнение OpenCL с CUDA и шейдерами для GPU, а также с OpenMP для CPU.
Тестирование проводилось на задаче N-тел. Она хорошо ложится на параллельную архитектуру, сложность задачи растёт как O(N 2 ), где N — число тел.
Задача
В качестве тестовой была выбрана задача симуляции эволюции системы частиц.
На скриншотах (они кликабельны) видна задача N точечных зарядов в статическом магнитном поле. По вычислительной сложности она ничем не отличается от классической задачи N тел (разве что картинки не такие красивые).
Во время проведения замеров вывод на экран был отключен, а FPS означает число итераций в секунду (каждая итерация — это следующий шаг в эволюции системы).
Результаты
Код на GLSL и CUDA для этой задачи был уже написан сотрудниками ННГУ.
NVidia Quadro FX5600
Версия драйвера 197.45 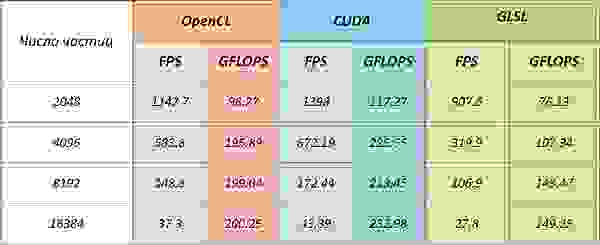
CUDA обгоняет OpenCL приблизительно на 13%. При этом, если оценивать теоретически возможную производительность для этой задачи для данной архитектуры, реализация на CUDA достигает её.
(В работе A Performance Comparison of CUDA and OpenCL говорится о том, что производительность ядра OpenCL проигрывает CUDA от 13% до 63% )
Несмотря на то, что тесты проводились на карточке серии Quadro, понятно, что обычный GeForce 8800 GTS или GeForce 250 GTS дадут схожие результаты (все три карточки основаны на чипе G92).
Radeon HD4890
ATI Stream SDK версия 2.01 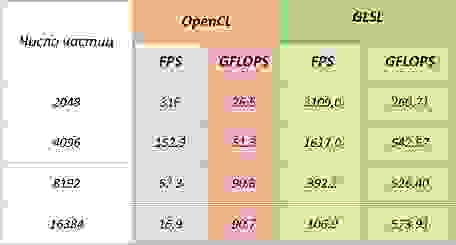
OpenCL проигрывает шейдерам на карточках от AMD так как вычислительный блоки на них имеют архитектуру VLIW, на которую (после оптимизации) могут хорошо лечь многие шейдерные программы, но компилятор для кода OpenCL (который является частью драйвера) плохо справляется с оптимизацией.
Также этот весьма скромный результат может быть вызван тем, что карточки от AMD не поддерживают локальную память на физическом уровне, а отображают область локальной памяти на глобальную.
Код с использованием OpenMP был скомпилирован при помощи компиляторов от Intel и Microsoft.
Компания Intel не выпустила своих драйверов для запуска кода OpenCL на центральном процессоре, поэтому был использован ATI Stream SDK.
Intel Core2Duo E8200
ATI Stream SDK версия 2.01 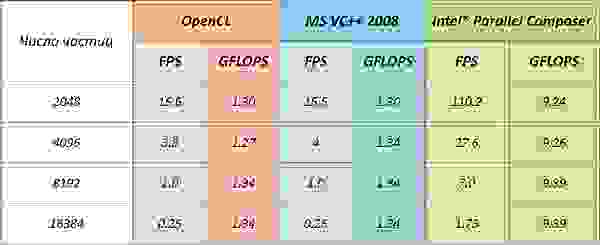
Код на OpenMP, скомпилированный при помощи MS VC++ имеет практически идентичную производительность с OpenCL.
Это ещё при том, что Intel не выпустил своего драйвера для интерпретации OpenCL, и используется драйвер от AMD.
Компилятор от Intel поступил не совсем «честно» он полностью развернул основной цикл программы, повторив его где-то 8k раз (число частиц было задано константой в коде) и получив семикратный прирост производительности также благодаря использованию SSE инструкций. Но победителей, конечно, не судят.
Что характерно, на моём стареньком AMD Athlon 3800+ код тоже запустился, но таких выдающихся результатов, как на Intel, конечно, ждать не приходится.
Заключение
Какую видеокарту применить для Blender, Cycles, Eevee: GeForce или Radeon?
Константин Шевцов 1
Пользователь сайта
Хочу собрать компьютер для работы в Blender.
Это будет десктопный компьютер. На нём будет Windows 10 Домашняя 64-bit.
В Blender буду делать 3D-моделирование. Рендеринг буду делать в Cycles и Eevee.
Какую видеокарту применить: GeForce или Radeon?

mageaster
Мастер

Vladislav Egorov
Мастер
Константин Шевцов 1
Пользователь сайта
mageaster, спасибо. Я принял к сведению.
Константин Шевцов 1
Пользователь сайта
Vladislav, спасибо. Я принял к сведению.
Смотритель
mageaster
Мастер
mageaster
Мастер
2 производительнее, чем 2060 при той же цене.
Константин Шевцов 1
Пользователь сайта
Спасибо всем за Ваши ответы. Принял к сведению.
Рассматриваю ещё вариант. Установить в компьютер две видеокарты. Одну видеокарту буду применять для 3D-моделирования в Blender, рендеринга в Cycles, рендеринга в Eevee. Другую видеокарту буду применять для перерисовки интерфейса Blender. Как вам такой вариант? Это возможно? Это работает? Это полезно для производительности? Это стабильно, надёжно?
Также, прошу, поясните следующие моменты.
Правильно ли говорить, что у Cycles есть интерфейс? Или у него нет интерфейса?
Правильно ли говорить, что у Eevee есть интерфейс? Или у него нет интерфейса?
Если у Cycles есть интерфейс, то как вам вариант: одну видеокарту буду применять для рендеринга в Cycles, другую видеокарту буду применять для перерисовки интерфейса Cycles? Это возможно? Это работает? Это полезно для производительности? Это стабильно, надёжно?
И, если у Eevee есть интерфейс, то как вам вариант: одну видеокарту буду применять для рендеринга в Eevee, другую видеокарту буду применять для перерисовки интерфейса Eevee? Это возможно? Это работает? Это полезно для производительности? Это стабильно, надёжно?
mageaster
Мастер
Это идеальный вариант, сам к такому стремлюсь.
Да, при условии, что обе видеокарты используют одну и ту же версию драйверов. Это может быть, допустим, какая-нибудь 1660 для вывода на экран и 2080Ti для рендера.
Нет, это всего лишь рендер-движки, которые используют интерфейс используемой программы (Cycles есть и для C4D, например, да и в Блендере он, на самом деле, плагин).
Смотритель

Бабуин
Мастер
Смотритель
mageaster
Мастер
Константин Шевцов 1
Пользователь сайта
Я понял так: поскольку ни у Cycles, ни у Eevee нет интерфейса, то ни в отношении Cycles, ни в отношении Eevee не может быть рассмотрен вариант о пользе двух видеокарт, перерисовки интерфейса. Я правильно понял?
Я сделал вывод: рассматривая Blender, Cycles, Eevee, можно говорить о пользе двух видеокарт для Blender, как для всей системы, но нельзя говорить о пользе двух видеокарт ни для Cycles, ни для Eevee непосредственно, потому что у них нет своих интерфейсов. Можно говорить о следующей пользе для Blender: пока идёт рендеринг, можно работать дальше. Одна видеокарта будет делать рендеринг, другая видеокарта, тем временем, будет отрисовывать интерфейс Blender. Правильно?
ЛМА, Бабуин, спасибо. Принял к сведению.
Русские Блоги
Строительство среды развития ГПУ (CUDA и OPTIX)
Вместе может быть реализован высокоскоростным параллельным расчетом GPU, и отражение в сцене в сцене рассчитывается для компенсации для Unity3D, а скорость обнаружения излучения слишком медленная и не может соответствовать требованиям производительности. Дефекты.

Примечание: Перезапуск компьютера возникает во время установки NVIDIA CUDA. После перезапуска продолжайте открывать установочный пакет и следуйте исходным настройкам для установки один раз.
Нужно зарегистрировать учетную запись и заполнить некоторую информацию. Также нужно скачать и установить программное обеспечение CMake
После завершения установки открыть следующий каталог C: \ ProgramData \ NVIDIA Corporation \ SPDIX SDK 7.0.0 \ SDK
Найдите файл cmakelists.txt в каталоге, перетащите в следующие инструменты для генерации желаемого проекта, я использую VS2019

Нажмите Настроить Generate и нажмите Открыть проект, чтобы открыть проект.
Поскольку привод компьютера C полон CUDA, он не будет продемонстрирован.
Хорошо, вы также можете установить диск D, попробуйте следующее:
Создание решений:
Установите OPTIXMutigpu, чтобы начать проект, результаты следующие:
Первая программа GPU успешна.
Интеллектуальная рекомендация
Tree Дерево отрезков линии】 COGS 2632
Ссылочный блогАвтор:dreaming__ldxИсточник: CSDN Портал последовательности операций 【Название описания】 Последовательность длины n, вес порядкового номера в начале равен 0, есть m операций Поддерживают.

PAT-A-1046 кратчайшее расстояние [префикс и]
The task is really simple: given N exits on a highway which forms a simple cycle, you are supposed to tell the shortest distance between any pair of exits. Input Specification: Each input fi.

Как нарисовать несколько линий ROC на одном графике?

Класс коллекции JAVA
Резюме JAVA-коллекции Один, коллекция 1. Характеристики коллекций: коллекции используются только для хранения объектов, длина коллекции является переменной, и в коллекции могут храниться объекты разны.

MySQL репликация главный-подчиненный + переключатель главный-подчиненный
MySQL репликация главный-подчиненный + переключатель главный-подчиненный 05 января 2018 10:46:35Протрите протирать прыжок Количество просмотров: 5183Более Персональная категория:база данныхЭксплуатаци.
OpenCL в Adobe Premiere Pro: насколько GPU быстрее CPU?
Привет, Гиктаймс! Открыв недавно для себя прекрасный мир ускорения обработки данных силами видеокарт с помощью OpenCL, я решил написать небольшой вводный материал для новичков, не знакомых с этой технологией на практике. В Интернете нередко встречаются вопросы «какой прирост производительности я получу?», но ответы бывают либо абстрактными, либо излишне теоретизированными.
Этот пост призван наглядно показать, как применение OpenCL способно ускорить рендеринг видео в программах видеомонтажа. Глубокого погружения в теорию и матан вы не встретите – подробных теоретических статей про OpenCL на Гиктаймсе и Хабре предостаточно и без меня. Здесь будет только описание задачи и результаты тестов, поэтому прошу относиться к тексту именно как к простому вводному гайду для начинающих.

Зачем оно нужно?
Современные видеокарты – это настоящие вычислительные монстры, вся мощь которых обычно тратится на игры. Неглупые люди смекнули, что если организовать программистам прямой доступ к вычислительным блокам видеочипов, то можно всю эту колоссальную мощь задействовать под любые другие задачи, а не только обработку 3D-графики.
Первой в реализации этой идеи преуспела компания NVIDIA со своей архитектурой параллельных вычислений CUDA (Compute Unified Device Architecture). При помощи расширенного синтаксиса языка C и особого компилятора разработчики получили возможность задействовать для вычислительных задач графический чип. AMD, в свою очередь, представила Stream SDK – свое фирменное видение CUDA.
Результат был феноменальный – процессы, связанные с обработкой медиаданных, что подразумевает высокий уровень распараллеливания, завершались в разы быстрее, чем в случае вычислений силами центрального процессора. Особенно явно преимущество GPU проявлялось при рендеринге в программах 3D-моделирования и видеообработке.
Год спустя после выхода CUDA консорциум Khronos Group выпустил фреймворк OpenCL. Фактически он должен был унифицировать код для доступа к вычислительным мощностям процессоров на разных архитектурах, включая видеоядра. С этого момента в профессиональный софт начала активно внедряться поддержка нового фреймворка.
На сегодняшний день OpenCL поддерживают программы Adobe, медиаконвертеры, ряд популярных 3D-рендеров, CAD и софт для математического моделирования.
Лучше CUDA или OpenCL?
Очень частый и очень интересный вопрос вынесен в подзаголовок. Эти две технологии, как непохожие братья. Как и многострадальный PhysX, CUDA – технология закрытая, поддерживаемая только чипами NVIDIA и далеко не всем специализированным ПО. OpenCL – экстраверт, код открыт любому энтузиасту, любое ПО с поддержкой вычислений на GPU по определению работает с OpenCL.
Программисты NVIDIA не лаптем щи хлебают – если взять две сферические видеокарты в вакууме с одинаковой производительностью, то CUDA на чипе NVIDIA показывает в среднем на 20% большую производительность, чем OpenCL на чипе AMD. Но есть, как говорится, нюанс – если CUDA от NVIDIA работает быстро и хорошо, то OpenCL на картах этой компании немного уступает скорости обработки OpenCL от AMD. Несколько лет назад ситуация была совсем плачевная, но со временем с помощью драйверов разрыв удалось наверстать. Тем не менее, удельная производительность NVIDIA GeForce в OpenCL до сих пор немного ниже таковой у AMD Radeon. Поэтому в самом дурном положении окажутся те, кто приобрёл карту NVIDIA для работы с приложением, поддерживающим исключительно OpenCL — сам адаптер выйдет дороже, а его эффективность может быть ниже, чем у Radeon. Такая игра свеч не стоит.

Железо
Прекрасный мир OpenCL я открыл для себя лишь этим летом, купив сразу две видеокарты AMD Radeon серии 300: SAPPHIRE NITRO R9 380 и SAPPHIRE Tri-X R9 390X. Одну из них планировалось сдать обратно в магазин в зависимости от результатов домашних тестов. Карты покупались для надомного видеомонтажа, выбор в сторону Radeon был вполне осознанным: с одной стороны, CUDA работает быстрее, чем OpenCL. С другой, как выяснилось, OpenCL поддерживается значительно большим количеством профессионального софта, чем CUDA, а производительность карт NVIDIA в OpenCL оставляет желать лучшего.

Из предложенного ассортимента карты SAPPHIRE мне понравились более остальных. В отличие от любителей референсного дизайна, SAPPHIRE использует в системе охлаждения классические вентиляторы, которые работают значительно тише референсных центробежных ветродуев – к таким у меня выработалась стойкая неприязнь после беглого знакомства с видеокартой-пылесосом Radeon 4870×2.
Дома при распаковке двух огромных коробок я почувствовал себя замшелым мастодонтом – видеокарты немаленькие. SAPPHIRE R9 390X так и вовсе огромная, с тремя вентиляторами и радиатором, превышающим размеры печатной платы. Сперва я даже поволновался, влезут ли эти монстры в мой корпус. К счастью, влезли, но из корзины для жестких дисков пришлось демонтировать один хард. Киловаттный блок питания также был не лишним – R9 390X требует два четырехконтактных разъема питания, а такой ток вытянет не каждый БП.

Если Adobe Premiere Pro CS4 был тяжким грузом в офисе, то дома можно было организовать рабочее пространство по своему вкусу. Едва ли я когда-нибудь задумался бы о покупке Premiere Pro, если бы Adobe не выкатила замечательную, на мой взгляд, систему подписки Creative Cloud. Теперь за 600 рублей в месяц я имею легальный и постоянно обновляемый Premiere Pro CC. И он-то, в отличие от офисного старикана, нативно поддерживает рендеринг с помощью OpenCL и CUDA!
Если ваша видеокарта работает с OpenCL или CUDA, то еще на стадии создания проекта в Premiere Pro можно выбрать рендер. За аппаратное ускорение отвечает Mercury Playback Engine GPU (OpenCL) или (CUDA). В уже готовом проекте рендер можно изменить через Project Settings из меню File.
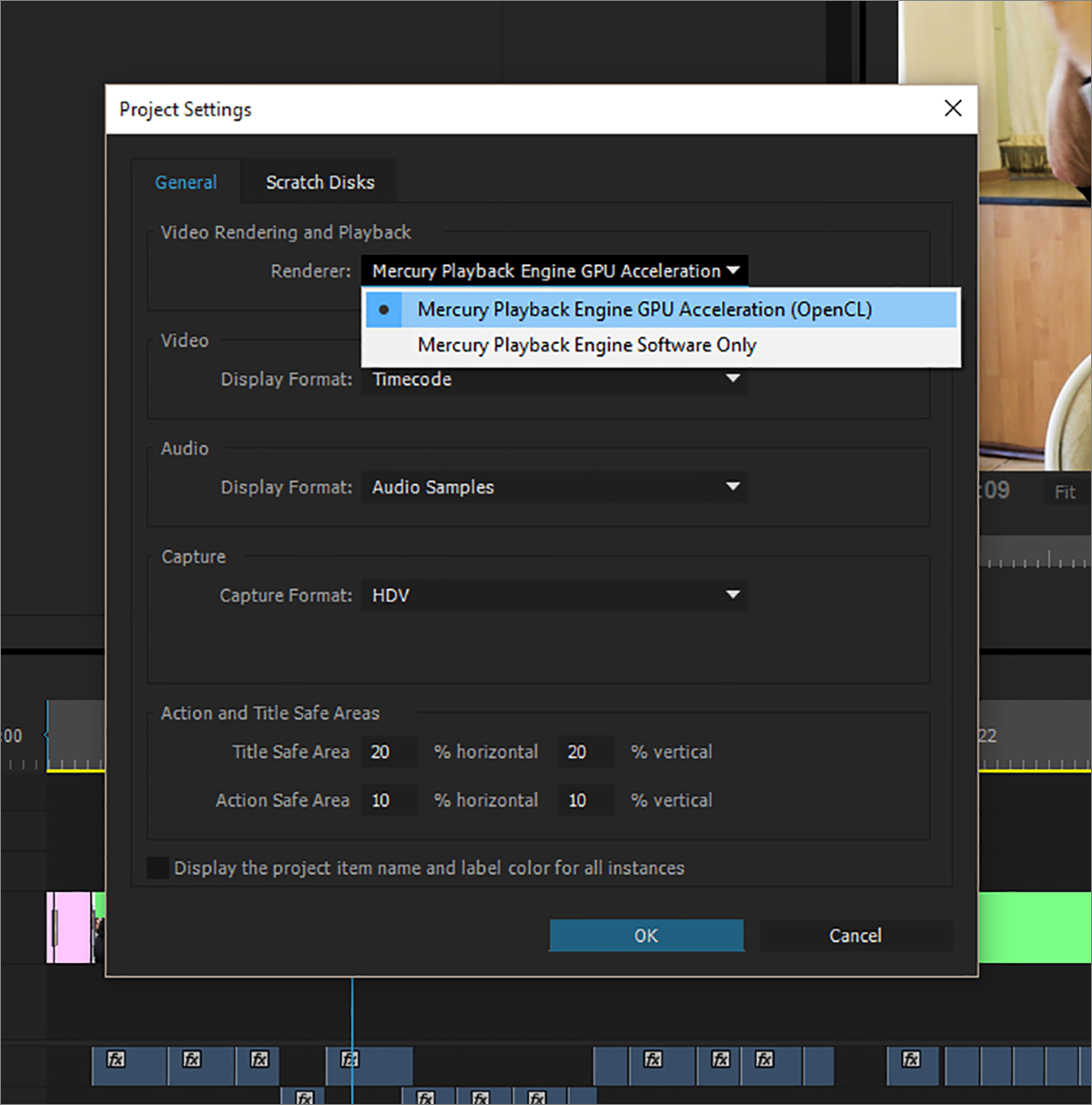
Как я уже говорил, с помощью OpenCL можно переложить на видеокарту вычисления по применению видеоэффектов. Однако не все эффекты в Premiere Pro поддерживают OpenCL – узнать об этом можно по наличию или отсутствию вот такого значка в списке.
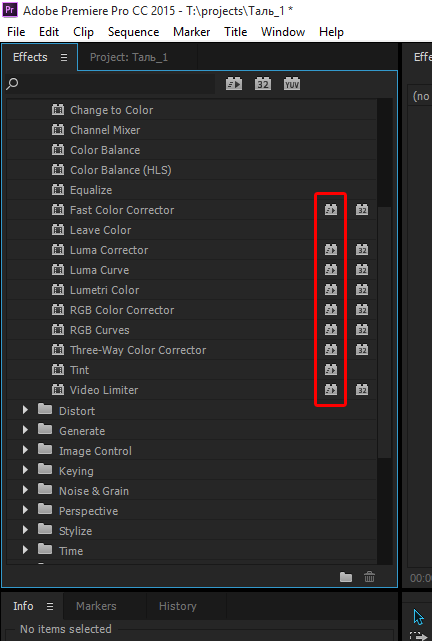
Тесты
В качестве тестового проекта я выбрал двухминутный ролик, состоящий из множества отрезков с видео Full HD с битрейтом 72 Мбит/с и фреймрейтом 24 кадра в секунду. Поверх всего этого безобразия был наложен ускоряемый эффект Lumetri Color, которым я провел цветокорррекцию. На выходе должен был получиться ролик в формате h.264, в разрешении 1920х1080 (то есть без изменений), битрейтом 6-7 Мбит/с, применялась двухпроходное кодирование.
Для подтверждения работы видеокарты я снимал параметры GPU-Z – глядя на частоту графического ядра, легко понять, когда рендеринг видео идет силами центрального процессора, а когда GPU.
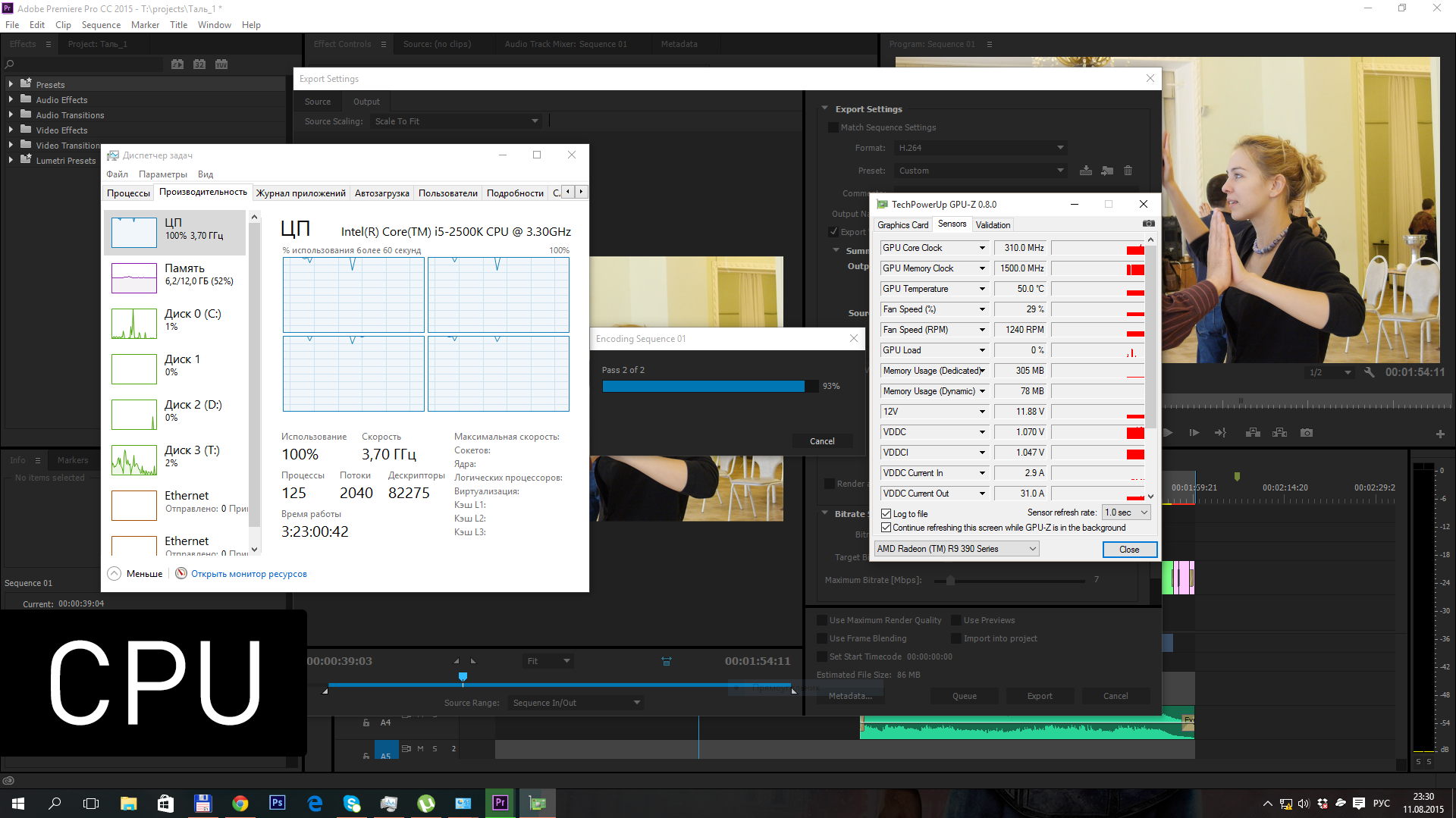
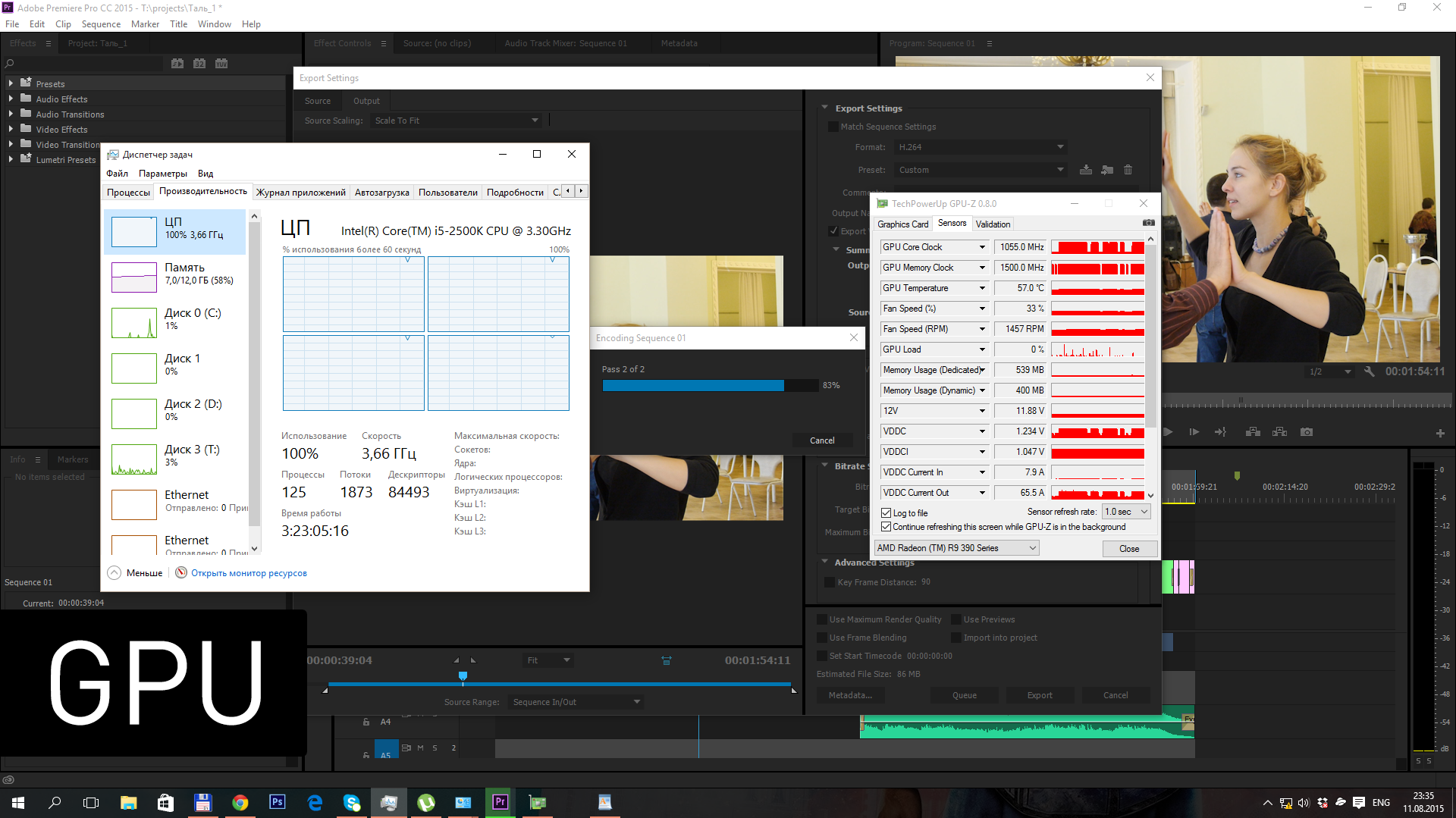
В первом тестовом прогоне я отключил эффект Lumetri Color, так что весь рендеринг заключался в изменении битрейта видео.
Прогон 1:
проект 2 минуты, h.264, 6-7 mbps, без эффектов
| CPU | 3:09 |
| SAPPHIRE Tri-X R9 390X | 2:33 |
| SAPPHIRE NITRO R9 380 | 2:38 |
Без применения эффектов разница в скорости рендеринга между процессором и мощной современной видеокартой очень невелика. При обработке видео общей длительностью около часа выигрыш от использования OpenCL будет более заметным, но все равно очень незначительным. Тем не менее, практически всегда в процессе монтажа к видео применяют эффекты цветокоррекции, поэтому данный тест стоит считать «синтетическим».
Прогон 2:
проект 2 минуты, h.264, 6-7 mbps, эффект Lumetri Color
| CPU | 11:33 |
| SAPPHIRE Tri-X R9 390X | 2:42 |
| SAPPHIRE NITRO R9 380 | 2:48 |
Результаты говорят сами за себя – если обе видеокарты играючи рендерили видео чуть медленнее риалтайма, то процессор на рендеринг каждой минуты тратил почти шесть минут. И это только с одним включенным эффектом! Если перед тестом я рассчитывал в том числе обработать часовой ролик с цветокоррекцией на всей продолжительности, то после полученных результатов от этой идеи решил отказаться. В своей работе я применяю цветокоррекцию для небольших отрезков видео, и час-два рендера меня не сильно напрягают. Терять же четыре-пять часов в тестовых целях мне было некогда.
Экстраполируя результаты, можно считать, что с цветокоррекцией длительностью 60 минут процессор справился бы за 4.5 часа, тогда как видеокартам потребовалось бы менее одного часа!
Выводы
По результатам тестов я оставил себе SAPPHIRE NITRO R9 380 – карта стоит заметно дешевле наикрутейшей R9 390X, но в Premiere Pro производительность двух адаптеров практически идентична. Учитывая, что адаптер покупался для выполнения работы, а значит зарабатывания денег, потраченных 17 тысяч рублей совсем не жалко. Тем более, что и в GTA V карта показала себя молодцом, но это тема совсем для другой заметки.
Что касается опыта применения OpenCL, то нельзя не признать – в мир видеомонтажа пришел спаситель: рендеринг превратился в удовольствие. По сравнению даже с разогнанным Intel Core i5, видеочипы играючи обрабатывают видео с наложенными эффектами в Premiere Pro. При таких результатах тестирования не стоит вопроса, использовать ли рендеринг силами GPU. Вопрос лишь в том, какую видеокарту под это приспособить. Что-нибудь из верхнего игрового сегмента будет в самый раз, например, AMD Radeon R9 3xx. Мои нужды полностью удовлетворил SAPPHIRE NITRO R9 380. Но адаптеры среднего и даже начального уровня также поддерживают OpenCL, а значит заметно ускорят вашу работу в профессиональном софте.
Все сцены, которые показываю в видео, можно скачать тут
В начале видео, я показываю, что качал Build от 28 августа, ведь именно тогда я начал запись этой серии =) Сейчас на сайте доступен более новый билд от 20 сентября.
Возможно, когда выйдет эта статья, там будет что-то поновее. Вот прямая ссылка на все билды.
Поэтому, чтобы тест сравнения с 2.93 был более точным, я включал “Progressive Refinement”.
Там же я заметил, что немного изменилась панель Denoiser и убрали “NLM” алгоритм.
Рендер в Blender 3 на CyclesX прошел за 2 минуты и 50 секунд.
Кстати, чтобы отрендерить в режиме “Progressive Refinement” пришлось выключить опцию “Adaptive Sampling” в этой версии.
При этом, можно заметить, что рендер бакетами на 2.93 прошел быстрее в 1.7 раза, чем на “Progressive Mode”.
Preview на сайте выглядит таким образом.
Тест этой сцены я делал 18 сентября. Именно тогда появился новый билд, в который вернули бакеты с помощью опции «AutoTiles».
Смотря на эту таблицу, я думаю можно сделать такие же выводы. =)
Во-первых, здесь видно, что RT-ядра рендерят быстрее в 3 раза!
Благодаря этому, я сделал нужные выводы и последующие сцены тестировал без этой опции.
А рендер на RT-ядрах быстрее почти в 2 раза.
Я немного внес изменения в эту сцену, чтобы протестировать IPR и был впечатлен результатом. Все достаточно быстро, что и можно наблюдать в видео на 14:28.
А таблица показывает, что рендер на RT-ядрах быстрее в 2.2 раза.
КТО Я?
Привет, меня зовут Андрей Кривуля Charly и я 3d-художник, который начал свой путь 3d-groom artist в 2016 году. До этого с 2009 по 2016 я занимался Environment art, интерьерами и много чем еще. Старые работы можно посмотреть здесь
Приятного просмотра!
С Уважением, Андрей Кривуля Charly.


