Сервер или облачное решение
Информация представляет особую ценность для бизнеса любого масштаба. По этой причине у каждой организации рано или поздно возникает проблема хранения имеющихся данных. Что лучше подойдет для этих целей: облако или сервер. Попытаемся разобраться, какое решение имеет больше плюсов и будет выгодным в конкретном случае.
Использование облачных технологий
Облако – относительно новая SaaS-технология, которая, тем не менее, достаточно быстро набирает обороты. Однако, несмотря на предположения экспертов, что к 2017 году на облачные технологии перейдет около 90-95% всех компаний, подобного до сих пор не случилось.
Использование облачного хранилища подразумевает, что всю информацию вы храните на сервере поставщика, а доступ к файлам получаете при помощи браузера или через специальную программу.
Облачная технология предполагает два решения: on-demand (облако производителя CRM системы) и private cloud (любое частное облако). Каждый из вариантов имеет особенности:
Основным достоинством облачных решений называют экономию денег и времени. При использовании подобной технологии вам не потребуется закупать оборудование, производить его обслуживание или замену. Также не потребуется содержание в штате системного администратора. То есть ваши затраты заключаются только в плате за используемые ресурсы облака.
Среди других плюсов подобного решения отмечают:
Благодаря этим преимуществам организации так или иначе применяют облачные сервисы в своих бизнес-процессах. Это – действительно просто и дешево, не требует от работников особых навыков и знаний. Но есть ли у подобного решения отрицательные стороны?
Облако подразумевает работу с файлами через интернет-соединение, то есть для просмотра данных необходим доступ к сети. Это может быть минусом, если у вас наблюдаются перебои в подключении. Следовательно, вы теряете доступ к информации и не можете работать.
Проблемы работы с файлами могут возникнуть и при недостаточной скорости соединения. Особенно, если происходит передача огромного массива данных, скорость является принципиальной.
Использование собственного или арендованного сервера
 Отдельный физический сервер (on-site) – более традиционное решение, которое постепенно уходит в прошлое. Связано это с тем, что затраты на его использование практически в 2 раза превышают расходы на облачное хранилище.
Отдельный физический сервер (on-site) – более традиционное решение, которое постепенно уходит в прошлое. Связано это с тем, что затраты на его использование практически в 2 раза превышают расходы на облачное хранилище.
On-site можно назвать максимально гибким решением для организации собственной ИТ-инфраструктуры, однако оно предполагает большие затраты. В них входит развертывание на серверах, последующее администрирование и обслуживание оборудования системными инженерами. Только в этом случае можно говорить о поддержании безотказной работы системы.
При этом существует два варианта использования сервера – это строительство собственного серверного узла (то есть закупка и установка машин в офисе компании) или аренда оборудования в дата-центре (то есть предоставление удаленного доступа к серверу на базе ЦОД).
Принципиальное преимущество собственного сервера заключается в максимальной свободе в выборе методов интеграции инфраструктуры с другими системами. Однако это предполагает, что вы несете дополнительные расходы на следующее:
Использование собственного сервера не рекомендовано компаниям, у которых нет квалифицированного IT-персонала или которые не имеют надежного подрядчика для аренды сервера. Но в том случае, если у вас имеется нужный работник, то вы можете обеспечить большую надежность системы, чем при использовании стороннего облачного хранилища.
Что выбрать в конкретном случае
При выборе облака или сервера для своей компании стоит тщательно взвесить все за и против. Сравним основные особенности каждого из решений:
Не требует установки / автоматически устанавливается при регистрации нового пользователя в облаке
Требует скачивания дистрибутива и его установки на сервере
Повышенная безопасность баз данных (обеспечивается силами пользователя или дата-центра)
Автоматическая установка обновлений
Единое администрирование облачных серверов силами провайдера
Управление оборудованием и программным обеспечением силами клиента или дата-центра
Отсутствие доступа к базе данных, сложности с масштабированием ресурсов
Отсутствие ограничений в доступности приложений, легкое масштабирование ресурсов при увеличении компании
Затраты на содержание
Отсутствие затрат на старте, арендная плата за используемые мощности
Большие затраты на старте, далее – расходы на обслуживание оборудования
Так или иначе, но каждый из вариантов имеет свои достоинства и недостатки. Облачные технологии станут оптимальным решением для организаций следующего типа:
Собственный сервер больше подходит в следующих случаях:
Надеемся, что теперь вы сможете понять, какой вариант хранения информации – облако или сервер – оптимально подойдет для вашей фирмы. А если у вас остались вопросы об описанных технологиях, то специалисты нашего дата-центра Xelent помогут разобраться во всех нюансах.
7 типичных ошибок при сравнении своих серверов с облаком
Многие сомневаются, что облака обходятся дешевле собственного железа — такую точку зрения мы в ActiveCloud встречаем довольно часто. Одни пользуются облаками из-за гибкости, вторые хотят уйти от рутины, третьим нужна централизация, четвёртым — безопасность. Однако облака не только удобны, но и выгодны, и мы попробуем объяснить почему.
При оценке эффективности перехода в облака Заказчики зачастую склонны сравнивать стоимость владения облаками и железом в лоб. Например, если покупаем 5 серверов с 40 процессорными ядрами и 256 ГБ RAM, то и у облачного провайдера запрашиваем аналогичные ресурсы (40*5=200 vCPU + 256*5=1280 ГБ vRAM), а потом сравниваем затраты за 3 года или даже 5 лет.
К сожалению, в большинстве случаев такой подход не будет объективным, поскольку не учитывает ряд важных нюансов, напрямую влияющих на стоимость владения.
1. Не учитываются ресурсы, требуемые для обеспечения отказоустойчивости
В облаке вопросы отказоустойчивости уже продуманы — хосты виртуализации кластеризованы, а в кластере зарезервированы ресурсы как минимум в размере одного хоста виртуализации, чтобы серверы клиентов в случае отказа хоста или его выключения на время регламентных работ могли быть перемещены на резервный хост. При этом дополнительной платы (сверх обозначенной стоимости ресурсов) за такой резерв сервис-провайдер не требует.

В случае своего железа потери на резервирование придётся вычесть из потенциально доступного на оборудовании пула ресурсов. В нашем примере с 5 серверами Заказчик при сохранении отказоустойчивости не сможет загрузить серверы по процессору и памяти более чем на 80%, иначе в случае отказа одного из хостов часть серверов физически не смогут быть перезапущены из-за нехватки ресурсов.
Конечно, можно рассчитывать, что в случае аварии вы сможете временно остановить ряд некритичных сервисов, но такой подход в реальных условиях как правило не работает.
То же самое справедливо и для облачного хранилища данных — в цену виртуального дискового пространства уже заложены устойчивые к множественным отказам типы рейдов и резервные диски горячей подмены, а в случае собственной СХД будут доступны для использования 45-65% от сырого дискового объема в зависимости от выбранного типа RAID-массива.
2. Не учитывается предел загрузки серверов и систем хранения данных
Практика показывает, что серверы архитектуры x86 не стоит постоянно нагружать более чем на 70-80% по процессору и 80-90% по памяти, иначе возможны просадки производительности, особенно заметные во время запуска обслуживающих задач (например, во время резервного копирования). При этом кратковременные всплески нагрузки железо, как правило, переживает нормально, а вот при долговременной работе в таком режиме деградация производительности размещённых на этом железе ИТ систем очень вероятна.
По этой причине многие сервисные провайдеры не только соблюдают правила допустимой предельной утилизации своего оборудования*, но и фиксируют такие обязательства в договоре с Заказчиком.
Выдержка из договора SLA для нашего облака VMware
На системе хранения данных утилизировать весь доступный объем, получившийся после сборки RAID-массивов, также не всегда получается, поскольку требуется резерв для работы различного функционала стораджа (например, аппаратных снапшотов или тиринга). Размер такого резерва может составлять 10% и более от доступного для адресации места.
При использовании СХД на механических дисках (HDD) размеченные луны не рекомендуется заполнять более чем на 70-80% при интенсивной дисковой нагрузке, чтобы избежать деградации производительности хранилища. SSD диски такой проблемы лишены, однако all-flash стораджи сегодня все еще достаточно дороги, и не для каждой компании их покупка рентабельна.
3. Не учитываются издержки, связанные с ограниченным масштабированием
Не секрет, что при планировании потребляемых ресурсов всегда закладывается определенный резерв на случай роста. Размер этого резерва индивидуален, однако влияющие на него факторы более-менее известны.
Можно отталкиваться от статистики роста потребления в предыдущие годы — если эти данные есть, то закладываем аналогичную динамику и немного сверху на непредусмотренные срочные инициативы бизнес-подразделений. Если такой статистики нет, то придётся делать предположение самостоятельно на основании плана будущих проектов и стратегии компании по росту и географической экспансии. Такой прогноз вряд ли окажется точным, но это все же лучше, чем оказаться без мощностей, нужных бизнесу «здесь и сейчас»
В период высокой конкуренции практически на всех b2c рынках, бизнес вынужден делать ставку на скорость запуска и вывода на рынок новых продуктов и услуг, потому как зачастую первый на рынке снимает сливки, а второй получает убытки.
В таких условиях поддерживать нужный темп, опираясь на собственную инфраструктуру, могут себе позволить только крупные игроки, способные инвестировать в собственную экспертизу, или даже ИТ платформу, и перераспределить ресурсы между проектами в случае необходимости.
Для менее крупных и средних компаний намного быстрее будет масштабироваться по мере необходимости на облачных мощностях, поскольку свое железо быстро нарастить не получится. Даже если в компании внедрены стандарты на оборудование и налажен процесс расчета конфигурации в выбранном вендоре, пройдет не менее 2-3 месяцев, прежде чем железо будет рассчитано, поставлено, смонтировано и настроено для возможной эксплуатации. Если же процедура приобретения основных средств достаточна сложна, как часто бывает, и корпоративные регламенты требуют каждый раз проводить тендер с участием нескольких конкурирующих производителей, то процесс расширения ресурсного пула легко может растянуться на полгода и более.
Конечно, в случае с облаком планировать и закладывать в бюджет резерв тоже нужно, однако при неверном планировании компания не понесёт заметных убытков — облачные мощности всегда можно масштабировать по реальному потреблению, и нет нужды оплачивать лишнее, пока оно реально не потребуется.
4. Не учитываются издержки на неточный сайзинг ключевых бизнес-систем
Точное планированием ресурсов для ключевых учётных информационные систем может быть сложной задачей, поскольку каждое внедрение индивидуально и часто сопряжено с большим объёмом доработок под конкретные бизнес-процессы. В этом случае при сайзинге остается надеяться на рекомендации разработчиков системы, которые обязательно заложат возможные риски — ведь им не хочется оправдываться перед Заказчиком за медленную работу системы после внедрения. Получив рекомендации производителя, собственные ИТ специалисты также заложат риски, потому что не хотят выслушивать упреки от пользователей. В итоге получается, что производитель перестраховался при предоставлении рекомендаций раза в полтора, и ИТ отдел перестраховался при заказе оборудования раза в полтора, а в результате приобретенное дорогостоящее железо простаивает больше чем на половину, и лишнее обратно в магазин уже не отнесешь.
Облако не только спасает от подобных ситуаций, но также может сильно облегчить жизнь тем, кто арендует мощности на время внедрения, выполняя таким образом сайзинг на реально развернутой системе. В этом случае, правда, появляются некоторые риски совместимости — после переезда на свое железо производительность системы может внезапно снизиться без видимых причин. Но такой подход все же лучше, чем покупка оборудования вслепую.
5. Не принимается в расчет стоимость обслуживания своей инфраструктуры
Любое железо, будь то сетевое оборудование, серверы или хранилища, нужно обслуживать. То же самое можно сказать в отношении систем виртуализации, мониторинга, безопасности, бекапирования и других сервисов, обеспечивающих стабильную и безопасную работу ключевых бизнес-систем компании. Персонал, способный поддерживать все это в рабочем состоянии и починить в случае аварии, стоит достаточно дорого. Зачастую — неоправданно дорого для не самого крупного бизнеса.
На основе статистических данных, в том числе HH.RU(https://stats.hh.ru).
При этом совокупная сложность используемого стека инфраструктурных технологий становится выше с каждым годом, и вместе с ней постоянно растут требования к квалификации обслуживающих специалистов.
Удерживать таких людей в штате даже при наличии пухлого бюджета становится все сложнее, поскольку стоящих специалистов помимо зарплаты необходимо также обеспечивать потоком задач с нарастающей сложностью и ответственностью. Конкурировать за них с профильными ИТ компаниями как правило попросту невыгодно.
Размещая инфраструктуру в облаке, Заказчик тем самым фактически получает доступ к разносторонней команде квалифицированных архитекторов и инженеров, опыт и компетенции которых постоянно растут. Чем плотнее компания взаимодействует с сервис-провайдером в своих проектах, тем в большей степени может рассматривать его не только как поставщика облачных услуг, но и как постоянно доступного ИТ партнера, готового делиться с клиентом опытом и комплексно решать его задачи.
Здесь важно отметить, что аренда мощностей и сервисов в облаке, конечно же, не освободит компанию от необходимости инвестировать в свою службу ИТ, однако позволит пересмотреть штат, выбирая специалистов с более узкими, профильными для ваших бизнес-систем компетенциями, перекладывая ответственность за инфраструктурные и пограничные сервисы на плечи провайдера.
6. Не всегда учитывается стоимость вендорской поддержки используемого ПО и оборудования
Каким бы именитым не был производитель, от производственного брака и ошибок в работе софта все равно не застрахован никто. Особенно бывает обидно, когда из-за этого не просто некорректно работает часть функционала, а невозможна эксплуатация приобретенных ИТ активов в целом, и оперативно решить вопрос с производителем не получается, даже если приобретена дорогая next business day поддержка.
Происходит такое по разным причинам: иногда у вендора ещё не выстроены процессы, и поддержка оказывается в ограниченном режиме, иногда нужных деталей нет в ЗИП, иногда требуются кастомные прошивки, на написание которых уходит не одна неделя, а то и не один месяц, — однако результат всегда один — потраченное время, нервы, сорванные сроки проекта и вызов на ковер к бизнесу. Думаю, многие согласятся, что переложить подобные риски на плечи провайдера намного приятнее.
7. Не учитывается стоимость постройки и содержания своей серверной
Облачные провайдеры обслуживают большое количество Заказчиков, и недоступность облака по любым причинам сильно бьет по деловой репутации поставщика услуг, даже если отказ произошел не по его вине. Клиентам все равно, какого размера дерево упало на датацентр, и какого цвета был экскаватор, повредивший оптику. Поэтому вопрос выбора и оснащения площадки как правило не стоит — арендуем Tier3 ЦОД и подключаем несколько Интернет-каналов с защитой от DDoS.
Даже если не ставить перед собой задачу построить серверную по мировым стандартам, а лишь обеспечить приемлемые условия эксплуатации для своего оборудования, то капитальные затраты все равно будут заметными — придется выделить помещение, проложить СКС, подключить пару внешних каналов связи, подвести качественные линии электропитания, способные выдержать десяток-другой киловатт, правильно организовать охлаждение и вентиляцию, позаботиться о ИБП, а в идеале задублировать основные инженерные системы и поставить промышленную систему пожаротушения и СКУД.
И конечно же все вышеперечисленное придется обслуживать, что вряд ли обойдётся дешевле четверти миллиона в год на каждую полную стойку.
Можно облегчить себе жизнь и разместить свое оборудование в коммерческом ЦОД. Однако преимущества аутсорсинга непрофильных ИТ операций достаточно быстро становятся очевидны, и от аренды стоек Заказчики переходят к гибриду своего железа и постепенно его заменяющих облачных сервисов.
Если при сравнении учесть описанные выше нюансы, то в большинстве случаев окажется, что облака позволяют бизнесу снизить издержки, даже если при выборе провайдера сделать акцент на качестве услуг и количестве доступных сервисов.
«Облака были созданы, потому что все задолбались»: в чём отличие облачной инфраструктуры от своих серверов
Публичные облака появились как ответ на мучения компаний, которые поддерживали парк собственных серверов. Слишком много проблем возникало с заказом оборудования, его настройкой и поддержкой, поэтому облачные вычисления быстро стали востребованными — так считает Александр Волочнев, Developer Advocate в DataStax и автор видеокурса по AWS в «Слёрме».
Боли сисадминов и бизнеса, а также возможности, которые принесли им облака, Александр Волочнев подробно описал на вебинаре «Создание эффективной инфраструктуры при помощи облачных решений». Запись вебинара есть на YouTube, здесь публикуем краткую выжимку.
Проблемы поддержки своей инфраструктуры
Поддерживая собственный парк серверов, мучались все: и разработчики, и саппорт, и сисадмины. Сисадминам доставалось больше остальных: серверов не хватало, а новых заказать не давали — бюджета нет; один инженер работал за десятерых; поддержка флота съедала всё время, его не оставалось на развитие; разработчики плохо оценивали нагрузку на инфраструктуру; заказанные с горем пополам серверы ехали по несколько месяцев.
Мучались не только рядовые сотрудники, но и управленцы: постоянно приходилось искать деньги на новое оборудование и одновременно — нормальных людей в команду; админы не развивали инфраструктуру, а только патчили текущий флот; БД работала медленно, клиенты были недовольны; сложно было оценить, сколько железа нужно под новый проект.
При поддержке своего парка серверов компании сталкивались и продолжают сталкиваться с несколькими крупными проблемами.
Медленные изменения. Расширение, масштабирование, добавление мощностей — на всё это нужно время. Оборудование надо заказывать за несколько недель или даже месяцев, оплата вперёд. Можно взять в аренду, но минимальный срок аренды — месяц, даже если сервер нужен на один день. Чаще аренда годовая. Любые операции требуют участия людей, а толковых всегда не хватает.
Высокая стоимость и низкая надёжность. Система либо хрупкая, либо очень дорогая. А часто и хрупкая, и дорогая.
Отсутствие гибкости по географии. Решение проблемы географической распределённости укладывается в схему ДДХ — долго, дорого, хреново. При этом без распределённости не будет отказоустойчивости. Если данные размещены в одном дата-центре, приложение нельзя назвать отказоустойчивым.
Например, AWS работает регионами и зонами доступности. Регион — это несколько центров обработки данных, размещенных вместе. Зона доступности — это конкретный ЦОД, обязательно удалённый от соседей, имеющий независимое подключение к интернету и энергопитанию. Вот это настоящая распределённость и отказоустойчивость.
Отсутствие гибкости по производительности. Свои серверы либо простаивают ¾ времени, либо в час пик не хватает мощностей, и всё лежит. 
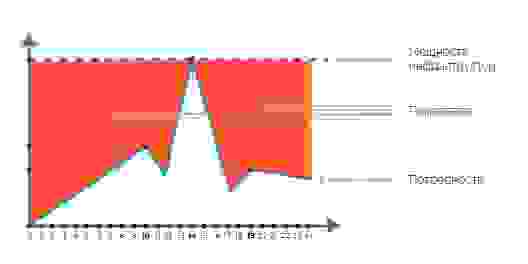
Режим экономии vs режим производительности: либо отказы в обслуживании на пике, либо переплата
Идеальная ситуация с точки зрения бизнеса — это когда закрыты и пики, и спады, и при этом нет переплат. С точки зрения инженеров — когда при первой необходимости есть возможность поднять новое окружение и грохнуть его, как только отпадёт нужда.
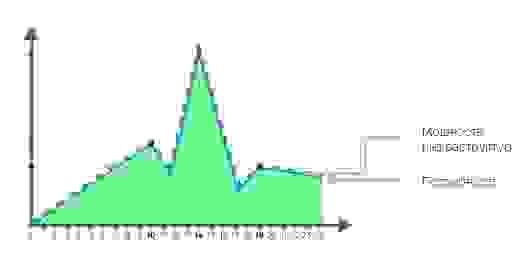
Идеальная ситуация: мощности и затраты на них меняются под задачи бизнеса
Как раз к такой идеальной ситуации и стремились в Amazon, где придумали облака. Для маркетплейса характерна сезонность нагрузок: ночью потише, днем потяжелее, плюс чёрная пятница и пик перед Рождеством. Площадка либо падает в пиковые нагрузки и теряет клиентов, либо весь год платит за инфраструктуру столько, сколько зарабатывает на пике. Со временем нашли выход — стали сдавать простаивающее железо в аренду, чтобы компенсировать расходы.
Так появился Amazon Web Services (AWS) и такой вид услуг, как облака.
Так облака появились, а востребованы они стали, потому что все — в буквальном смысле — задолбались.
Что такое облако
Предположим, компании нужно организовать работу с данными, и руководство решает создать собственную инфраструктуру. Компания строит свой ЦОД или арендует место в коммерческом дата-центре. Закупает и устанавливает серверы. Настраивает хранилища и сети. Далее занимается виртуализацией, установкой операционных систем, баз данных и прочего софта, необходимого для работы конечных приложений.
Теперь представим, что вместо этого руководство выбирает IaaS (Infrastructure as a Service, инфраструктура как услуга). В этом случае часть задач по организации инфраструктуры забирает облачный провайдер. ЦОД уже есть, он построен и отвечает самым высоким требованиям надёжности (по крайней мере, в случае с крупными провайдерами вроде AWS или Google Cloud). Хранилища, сети и виртуализацию тоже настраивает провайдер.
Таким образом компании остаётся только подготовка окружения для работы с данными и их администрирование. У инженеров освобождается время на развитие, улучшение, прокачку, оптимизацию. Они начинают больше участвовать в процессе разработки, появляется DevOps.

Распределение по обязанностям
Со временем облачные провайдеры развивали услуги и в дополнение к IaaS появились такие подходы, как Platform as a Service (платформа как сервис) и Software as a Service (приложение как сервис).
Для примера предположим, что в компании разработали приложение и хотят его запустить. В случае с IaaS, нужно войти в веб-интерфейс AWS, создать виртуальную машину. Операционная система уже будет установлена, но настраивать её придётся самостоятельно. Самим придётся устанавливать необходимый софт и разбираться в работе с данными.
В случае с PaaS всё необходимое уже установлено, остаётся только управлять своим приложением и данными. Уже легче, и админов для поддержки нужно меньше. PaaS подойдет не для всех, но точно будет полезен стартапам, которым надо быстро развернуться и некогда думать о железе.
И наконец, Software as a Service — приложение как сервис, когда вы просто используете какую-то услугу и не заботитесь ни о чём.
Дополнительные возможности
Особенности облака: «чёртова магия!»
Рассмотрим ключевые особенности облаков. В примерах часто упоминается Amazon Web Services (AWS), потому что с этой компании всё началось, и сейчас они лидеры на рынке облачных услуг.
On-Demand Self-Service — самообслуживание. Возможность по требованию, ни к кому не обращаясь, получить всё необходимое. Без телефонных звонков, без пересылки документов почтой, без ожидания в несколько месяцев — сразу.
Fast Flexibility (0 → 100 → 10) — «быстрая» гибкость. Сегодня компания не арендует ни одного сервера, завтра возьмёт сто машин, а послезавтра — десять. Очень быстро и гибко.
Resource Pooling — шаринг ресурсов. На одном железном сервере могут храниться данные разных компаний: профили нагрузки не совпадают, и они друг другу не мешают, зато оба платят меньше, чем за выделенный сервер — концепция многоквартирного дома. Однако не все любят многоквартирные дома. Тогда можно сказать: «хочу выделенный сервер», и вы это получите. Естественно, цена будет выше.
Elastic Scalability — гибкая масштабируемость. Сегодня нужно 10 серверов, завтра понадобится 100, послезавтра снова 10. С облаками не надо думать, где взять столько. Можно просто использовать и закрывать, когда необходимость отпадёт.
Measured Service — измеряемый сервис. Потребление ресурсов измеряется до бита и микросекунды, чтобы пользователь действительно оплачивал только то, что было потреблено. AWS первыми ввели посекундную тарификацию серверов.
Pay as you Go — оплата по мере потребления. Большинство облачных провайдеров берут оплату постфактум. Но если пользователь знает, что сервер будет нужен и завтра, и через год, он может платить и по-другому: сразу за весь период или по частям. За это предусмотрена скидка.
В AWS есть три способа получить сервер: on-demand — оплата по факту потребления; reserved — оплата за год вперёд, целиком или частями; spot instances — оплата по типу аукциона. В последнем случае пользователи устанавливают цену, которую готовы платить за Spot Instance, и сервер уходит к тому, кто заплатил больше. Система не самая надёжная, зато скидки могут достигать 90%. Spot Instance подходит для отложенного выполнения задач, когда скорость обработки не так важна, как стоимость.
На облаках можно экономить, но это не значит, что вы точно на них сэкономите. Во-первых, у облачных провайдеров бывают очень странные системы оплаты, в которых легко запутаться. Во-вторых, если забыть вырубить флот серверов, который был не нужен с четверга по вторник, то за него придётся заплатить. При плохом стечении обстоятельств в облаке можно сжечь гораздо больше денег, чем вы тратили в собственных ДЦ. Имейте это в виду.
Global Availability / Distribution — глобальная доступность. AWS имеет 22 региона и 77 центров обработки данных по всему миру, плюс около 200 точек присутствия. Похожая инфраструктура у Azure и Google Cloud. Благодаря этому клиенты облачных сервисов могут использовать свои приложения, управлять своими данными глобально. Если компания работает в одном регионе, а клиенты живут в другом, тогда можно настроить всё так, чтобы подключение от клиента шло сначала во внутреннюю сеть AWS и оттуда уже на высоких скоростях попадало в регион компании.
Programmable Access / Management — программный доступ и программное управление. Раньше для заказа серверов приходилось звонить поставщикам, объяснять свои задачи, ждать коммерческое предложение, опять звонить… Связаться с AWS по телефону может только очень крупный клиент. Время стоит дорого, поэтому всё делается через веб-интерфейс, интерфейс командной строки и программный менеджмент.
Если нужно оптимизировать мощности серверов в зависимости от трафика, то достаточно один раз настроить AutoScaling Group — группу автоматического масштабирования для серверов, мониторинг и триггеры. После этого AWS будет сам создавать и удалять серверы в зависимости от нагрузки. Клиент получает масштабирование с минимальной переплатой и полностью автоматическим управлением.
«Программный доступ, программирование вашей инфраструктуры — это реально чертова магия, я это просто обожаю!»
AWS предлагает около 250 служб для самых разных задач. Если говорить про инфраструктуру, то здесь есть и базы данных, и сетевые хранилища, и вообще всё. Нет такой отрасли, для которой они еще что-то не предложили. Посмотрите на скриншот, в левом нижнем углу есть вкладка «Satellite» — управление спутниками. То есть при желании в AWS можно работать со спутниками!
Услуги AWS
Фактически в AWS есть всё, что может потребоваться в разработке. Хотите организовать работу микросервисов — пожалуйста, на базе AWS существует целый фреймворк. В современных приложениях 99% кода — это повторение уже написанного. Чтобы не повторяться, можно прийти в AWS и пользоваться.
Облачные провайдеры
AWS, Microsoft Azure и Google Cloud — самые популярные облачные провайдеры. Но помимо них существует более десяти крупных поставщиков облачных услуг.
Amazon высадились первыми, и они продолжают занимать около половины рынка. Microsoft Azure присоединились с большим опозданием, но сейчас каждый пятый клиент пользуется именно ими. Google Cloud Platform немножко от них отстают, но в принципе незначительно. Распределение облачных провайдеров на рынке
Кто из них лучше? Я не буду отвечать на этот вопрос, потому что для ответа нужно учесть столько факторов и нюансов, что не хватит двадцати вебинаров и двадцати специалистов (в конце концов специалисты передерутся и к одному решению не придут). Google Cloud считается дешевле Amazon, и это логично: если ты приходишь на рынок, который уже занят, то с высокими ценами шансов у тебя не будет. Насколько я знаю, сейчас Google Cloud самое быстро растущее облако.
Некоторые компании предпочитают использовать Hybrid Cloud и Multicloud. Multicloud подразумевает, что ресурсы рассредоточены по нескольким облакам. Его организуют, чтобы сэкономить и обеспечить отказоустойчивость. Если один тип обработки дешевле в Google Cloud, второй тип на Amazon, то распределять данные выгоднее, чем держать в одном сервисе. Хотя надо учитывать, что передача больших объемов данных между облаками может стоить дорого.
Для отказоустойчивости дублируют данные в хранилищах двух провайдеров, чтобы при падении одного второй подстраховал. Но есть вероятность, что подобное дублирование будет стоить гораздо дороже, чем потери в случае простоя.
Как попробовать
У всех поставщиков есть бесплатный доступ, в рамках которого можно попробовать все услуги. Создать большие хранилища не получится, но для теста бесплатных мощностей точно хватит.
На курсе по администрированию облачных систем мы рассказываем о принципах работы в AWS и учим развёртывать системы с автоматическим масштабированием. Видеокурс вышел в январе 2021. Он будет полезен разработчикам, DevOps, сисадминам. Архитекторам и техническому руководству тоже пригодится: чтобы сэкономить время, можно пропустить практику, а сосредоточиться на теории и демонстрациях. Они помогут понять, как работает AWS и как его использовать в компании.


