Содержание урока
§1. Информатика и информация
§2. Что можно делать с информацией?
Введение
§3. Измерение информации
§2. Что можно делать с информацией?
Введение
Как мы уже знаем, информация сама по себе нематериальна. Поэтому она может существовать только тогда, когда связана с каким-то объектом или средой, т. е. с носителем.
 Материальный носитель — это объект или среда, которые могут содержать информацию.
Материальный носитель — это объект или среда, которые могут содержать информацию.
Изменения, происходящие с информацией (т. е. изменения свойств носителя), называются информационными процессами. Все эти процессы можно свести к двум основным:
— передача информации (данные передаются с одного носителя на другой);
— обработка информации (данные изменяются).
Часто информационными процессами называют также и многие другие операции с информацией (например, копирование, удаление и др.), но они, в конечном счёте, сводятся к двум названным процессам.
Для хранения информации тоже используется какой-то носитель. Однако при этом никаких изменений не происходит, поэтому хранение информации нельзя назвать процессом.
Следующая страница  Передача информации
Передача информации
Cкачать материалы урока
§ 2. Действия с данными
Понять, чем отличаются действия с информацией от действий с данными.
Научиться рассуждать о действиях с данными и выполнять эти действия, в том числе с помощью компьютера.
Повторить
С информацией человек может осуществлять разные действия: получать информацию, наблюдая за объектами реальной действительности, запоминать ее.

Можно передать информацию с помощью устного сообщения, обработать её в уме.
Обработать информацию в уме — это, например, поработать с текстом: понять его смысл, выполнить анализ текста с целью найти ошибки и исправить их, выделить главное в тексте и так далее.
Обработать информацию — это также означает проанализировать изображение: назвать нарисованные объекты, найти общие признаки этих объектов, определить, чем они отличаются, чем похожи, то есть сравнить их.

Данные — это закодированная информация, представленная на том или ином носителе — на камне, бумаге, стеклянной посуде, одежде, DVD-диске — в виде текстов, рисунков, чисел.
Тексты, рисунки, числа — это данные.
Данные, если они представлены на таких носителях, как, например, камень или бумага, можно рассматривать, анализировать, сравнивать как обычные объекты реальной действительности.
Рассматривать, анализировать, сравнивать данные — это действия с информацией, которые человек осуществляет в уме.
Информация хранится в памяти людей, поэтому действия с информацией люди могут выполнять только в уме.
Текстовые, числовые, графические и звуковые данные хранятся на носителях, в том числе электронных. Электронные носители — это оперативная память компьютера, жёсткий диск, CD- или DVD-диски, флэш-память и так далее. Поэтому разные действия с данными можно выполнять с помощью компьютера.
Данные хранятся на носителях, в том числе электронных, поэтому с ними можно работать с помощью компьютера.

Такой носитель информации, как камень, — твёрдый и тяжёлый. Поэтому данные на таком носителе нелегко создавать, изменять или переносить с места на место.
С данными, представленными на бумаге, работать легче. На бумажном носителе легко создать текст, рисунок. Можно представить информацию в виде чисел. Данные на бумаге удобно хранить и пересылать обычной почтой.

Звуковые данные можно передать с помощью колокола или барабанного боя. Но с помощью колокола или барабана их нельзя сохранить.

С помощью компьютера любые данные легко создавать, обрабатывать, хранить-копировать, пересылать. Электронные данные можно удалять из электронного документа или из памяти компьютера. Их можно вставлять в документ.
Электронные данные (текстовые, графические, звуковые) можно передавать по электронной почте. Для этого нужен компьютер или современный мобильный телефон, которые имеют выход в сеть Интернет.

Рис. Современные мобильные телефоны
По электронной почте можно посылать данные любого вида, если они закодированы и хранятся в памяти компьютера или мобильного телефона.
Много хороших свойств имеют электронные данные. Но есть и неудобства — с электронными данными нельзя работать без компьютера.
Выполни
Действия с информацией
Смысл действия с информацией
Понаблюдать за объектом, послушать рассказ об объекте, прочитать
Запомнить полученную информацию, закодировать знаками, рисунками, цифрами на носителе
Выполнить смысловой анализ информации по её свойствам: по новизне, по понятности, по важности; назвать общее, выделить отличия, выделить главное, существенное
Получить данные на носителе непосредственно из рук другого человека, обычной почтой или по электронной почте, найти документ в шкафу или в Интернете и так далее
Спрятать в коробке, в ящике стола, в шкафу или скопировать на жёсткий диск своего компьютера, CD-или DVD-диск, флэш-память и так далее
Главное
Знать
Уметь
Выполни задания в рабочей тетради №1
Выполни на компьютере задания к параграфу из раздела УМЕТЬ компакт-диска.
Прочитай на досуге в книге «Расширь свой кругозор» текст «Как сравнивать действия».
Что можно делать с данными в информатике
Всё, что нас окружает, и с чем мы ежедневно сталкиваемся, относится либо к физическим телам, либо к физическим полям. Известно, что все физические объекты находятся в состоянии непрерывного движения и изменения, которое сопровождается обменом энергией и её переходом из одной формы в другую. Все виды энергообмена сопровождаются появлением сигналов, то есть, все сигналы имеют в своей основе материальную энергетическую природу. При взаимодействии сигналов с физическими телами в физических телах возникают определённые изменения свойств – это явление называется регистрацией сигналов. Такие изменения можно наблюдать, измерять или фиксировать иными способами. При этом возникают и регистрируются новые сигналы, то есть, образуются данные.
Обработка данных адекватными им методами создаёт новый продукт – информацию. Таким образом, информация возникает и существует в момент взаимодействия объективных данных и субъективных методов. Как и всякий объект, она обладает свойствами (объекты различимы по своим свойствам). Характерной особенностью информации, отличающей её от других объектов природы и общества, является то, что на свойства информации влияют как свойства данных, составляющих её содержательную часть, так и свойства методов, взаимодействующих с данными в ходе информационного процесса. По окончании процесса свойства информации переносятся на свойства новых данных, то есть свойства методов могут переходить на свойства данных.
Итак, информация – это продукт взаимодействия данных и адекватных им методов.
1.2. Операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций. В структуре возможных операций с данными можно выделить следующие операции:
1.3. Виды и типы данных
Данные могут быть представлены следующими видами:
В зависимости от вида данных, они могут подразделяться на следующие типы:
1.4. Кодирование данных двоичным кодом
где N – количество независимых кодируемых значений;
m – количество разрядов двоичного кодирования.
1.4.1. Кодирование целых и действительных чисел
Двоичный код целого числа можно получить путём деления числа на 2 до тех пор, пока частное не будет равно 1. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного целого числа.
| 47: 2=23+1 | 252: 2=126+0 |
| 23: 2=11+1 | 126: 2=63+0 |
| 11: 2=5+1 | 63: 2=31+1 |
| 5: 2=2+1 | 31: 2=15+1 |
| 2: 2=1+0 | 15: 2=7+1 |
| 7: 2=3+1 | |
| 3: 2=1+1 | |
| Итак: 4710=1111012 | 25210=001111112. |
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Для кодирования чисел от 0 до 65535 потребуется 16 разрядов (16 бит). Используя 24 разряда (24 бита), можно закодировать более 16,5 миллионов разных значений.
1.4.2. Кодирование текстовых данных
Если каждому символу присвоить порядковый номер (целое число), то с помощью двоичного кода можно кодировать любые текстовые данные. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы закодировать комбинациями 8 битов все символы английского и русского алфавитов (строчные и прописные), арабские цифры, знаки препинания, символы арифметических действий и некоторые общепринятые специальные символы.
С этой целью институт стандартизации США (ANSI – American National Standard Institute) ввёл в действие систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования – базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 по 255.
Первые 32 кода (от 0 до 31) базовой таблицы выделены производителям аппаратных средств (в первую очередь компьютеров и печатающих устройств). Это управляющие коды, которым не соответствуют никакие символы, ими можно управлять работой технических устройств.
Коды от 32 по 127 предназначены для кодирования символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Символы русского алфавита и другие специальные символы кодируются кодами расширенной таблицы от 128 по 255.
Однако, рассмотренная выше система кодирования ASCII, не обеспечивает кодирование алфавитов многих других языков планеты. С целью устранения этого недостатка в настоящее время создана универсальная система – UNICODE, основанная на 16 – разрядном кодировании символов. Эта система позволяет обеспечить уникальные коды для 65536 различных символов. Этого количества достаточно для размещения в одной таблице символов большинства различных алфавитов планеты.
1.4.3. Кодирование графических данных
Если графическое изображение рассматривать как комбинацию мельчайших точек, образующих определённый узор, называемый растром. То с помощью линейных координат и индивидуальных свойств каждой точки, выраженных с помощью целых чисел, можно применить систему двоичного кодирования и для графических данных. К индивидуальным свойствам точки относятся яркость и цвет.
Чёрно – белые иллюстрации представляются в виде комбинации точек с 256 градациями серого цвета. Таким образом, для кодирования яркости любой точки достаточно 8 разрядов двоичного числа.
1.4.4. Кодирование звука
1.5. Основные структуры данных
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, то есть образуют заданную структуру. Существует три основных типа структур данных: линейная, табличная и иерархическая. При создании любой структуры данных необходимо обеспечить решение двух задач: как разделять элементы данных между собой и как разыскивать нужные элементы.
Линейные структуры – это хорошо знакомые списки. Список – это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим уникальным номером в массиве (списке).
Табличные структуры данных подразделяются на двумерные и многомерные.
Двумерные табличные структуры данных (матрицы) – это упорядоченные структуры, в которых адрес элемента определяется номером столбца и номером строки, на пересечении которых находится ячейка, содержащая искомый элемент.
Многомерные таблицы – это упорядоченные структуры данных, в которых адрес элемента определяется тремя и более измерениями. Для отыскания нужного элемента в таких таблицах необходимо знать параметры всех измерений (размерностей).
Линейные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задаётся числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения таких данных является сортировка. Недостатком простых структур данных является трудность их обновления. При добавлении, например, произвольного элемента в упорядоченную структуру возникает необходимость изменения адресных данных у других элементов.
Иерархические структуры – это структуры, объединяющие нерегулярные данные, которые трудно представить в виде списка или таблицы. В иерархической структуре адрес каждого элемента определяется маршрутом, ведущим от вершины структуры к данному элементу. Эти структуры по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путём создания новых уровней. Недостатком иерархических структур является относительная трудоёмкость записи адреса элемента данных и сложность упорядочения. Поэтому для упорядочения в таких структурах применяется метод предварительной индексации. При этом каждому элементу данных присваивается свой уникальный индекс, который используется при поиске, сортировке и тому подобное. В качестве примера иерархической структуры может служить система почтовых адресов.
1.6. Единицы представления, измерения, хранения и передачи данных
Одной из систем представления данных, принятых в информатике и вычислительной технике является система двоичного кодирования. Наименьшей единицей такого представления является бит ( двоичный разряд ).
Более крупные единицы измерения данных образуются добавлением префиксов кило-, мега-, гига-, тера-.
1 Килобайт (Кбайт) = 1024 байт = 2 10 байт.
1 Мегабайт (Мбайт) = 1024 Кбайт = 2 20 байт.
1 Гигабайт (Гбайт) = 1024 Мбайт = 2 30 байт.
1 Терабайт (Тбайт) = 1024 Гбайт = 2 40 байт.
В более крупных единицах пока нет практической надобности.
В качестве единицы хранения данных (информации) принят объект переменной величины, называемый файлом
Поскольку в определении файла нет ограничений на его размер, то можно представить себе файл, имеющий 0 байтов (пустой файл), и файл, имеющий любое число байтов. В определении файла особое внимание уделяется имени. Имя файла фактически несёт в себе адресные данные, без которых, данные, хранящиеся в файле, не станут информацией из-за отсутствия методов доступа к ним. Кроме адресных функций, имя файла может хранить сведения о типе данных, заключённых в нём.
Требование уникальности имени файла в вычислительной технике обеспечивается автоматически – создать файл с именем, тождественным уже существующему, не может ни пользователь, ни автоматика. Уникальность имени файла обеспечивается тем, что полным именем файла считается собственное имя файла вместе с путём доступа к нему.
Хранение файлов организуется в иерархической структуре, которая называется файловой структурой, В качестве вершины структуры служит имя носителя, на котором сохраняются файлы. Далее файлы группируются в каталоги (папки), внутри которых могут быть созданы вложенные каталоги (папки). Путь доступа к файлу начинается с имени устройства и включает все имена каталогов (папок), через которые проходит. В качестве разделителя используется символ “\“ (обратная косая черта).
Синтаксис записи полного имени файла:
Передача данных в компьютерных системах измеряется её скоростью. Единицей измерения скорости передачи данных через последовательные порты является: бит в секунду (бит/с, Кбит/с, Мбит/с). Единицей измерения скорости передачи данных через параллельные порты является байт в секунду (байт/с, Кбайт/с, Мбайт/с).
Что можно делать с информацией?
Все эти процессы, связанные с определенными операциями над информацией, называются информационными процессами.
Какими свойствами обладает информация?
Информация достоверна, если она отражает истинное положение дел. Недостоверная информация может привести к неправильному пониманию или принятию неправильных решений.
Достоверная информация со временем может стать недостоверной, так как она обладает свойством устаревать, то есть перестаёт отражать истинное положение дел.
Информация полна, если её достаточно для понимания и принятия решений. Как неполная, так и избыточная информация сдерживает принятие решений или может повлечь ошибки.
Точность информации определяется степенью ее близости к реальному состоянию объекта, процесса, явления и т.п.
Ценность информации зависит от того, насколько она важна для решения задачи, а также от того, насколько в дальнейшем она найдёт применение в каких-либо видах деятельности человека.
Только своевременно полученная информация может принести ожидаемую пользу. Одинаково нежелательны как преждевременная подача информации (когда она ещё не может быть усвоена), так и её задержка.
Если ценная и своевременная информация выражена непонятным образом, она может стать бесполезной.
Информация становится понятной, если она выражена языком, на котором говорят те, кому предназначена эта информация.
Информация должна преподноситься в доступной (по уровню восприятия) форме. Поэтому одни и те же вопросы по разному излагаются в школьных учебниках и научных изданиях.
Информацию по одному и тому же вопросу можно изложить кратко (сжато, без несущественных деталей) или пространно (подробно, многословно). Краткость информации необходима в справочниках, энциклопедиях, учебниках, всевозможных инструкциях.
Что такое обработка информации?
| Обработка информации — получение одних информационных объектов из других информационных объектов путем выполнения некоторых алгоритмов [15]. |
Обработка является одной из основных операций, выполняемых над информацией, и главным средством увеличения объёма и разнообразия информации.
Средства обработки информации — это всевозможные устройства и системы, созданные человечеством, и в первую очередь, компьютер — универсальная машина для обработки информации.
Компьютеры обрабатывают информацию путем выполнения некоторых алгоритмов.
Живые организмы и растения обрабатывают информацию с помощью своих органов и систем.
Что такое информационные ресурсы и информационные технологии?
| Информационные ресурсы — это идеи человечества и указания по их реализации, накопленные в форме, позволяющей их воспроизводство. |
Это книги, статьи, патенты, диссертации, научно-исследовательская и опытно-конструкторская документация, технические переводы, данные о передовом производственном опыте и др. [42].
Информационные ресурсы (в отличие от всех других видов ресурсов — трудовых, энергетических, минеральных и т.д.) тем быстрее растут, чем больше их расходуют.
| Информационная технология — это совокупность методов и устройств, используемых людьми для обработки информации. |
Человечество занималось обработкой информации тысячи лет. Первые информационные технологии основывались на использовании счётов и письменности. Около пятидесяти лет назад началось исключительно быстрое развитие этих технологий, что в первую очередь связано с появлением компьютеров.
В настоящее время термин «информационная технология» употребляется в связи с использованием компьютеров для обработки информации. Информационные технологии охватывают всю вычислительную технику и технику связи и, отчасти, — бытовую электронику, телевидение и радиовещание.
Они находят применение в промышленности, торговле, управлении, банковской системе, образовании, здравоохранении, медицине и науке, транспорте и связи, сельском хозяйстве, системе социального обеспечения, служат подспорьем людям различных профессий и домохозяйкам.
Народы развитых стран осознают, что совершенствование информационных технологий представляетсамую важную, хотя дорогостоящую и трудную задачу.
В настоящее время создание крупномасштабных информационно-технологических систем является экономически возможным, и это обусловливает появление национальных исследовательских и образовательных программ, призванных стимулировать их разработку.
Дата добавления: 2018-06-27 ; просмотров: 2231 ; Мы поможем в написании вашей работы!
ЦП Автоматизированные системы управления и промышленная безопасность
БК Автоматизированные системы управления и кибернетика
35. Основные операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
• сбор — накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация — приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация — отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка — упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
• архивация — организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита — комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой.
Технологии доступа при выполнении действий изменения элемента показана на рис. 79.
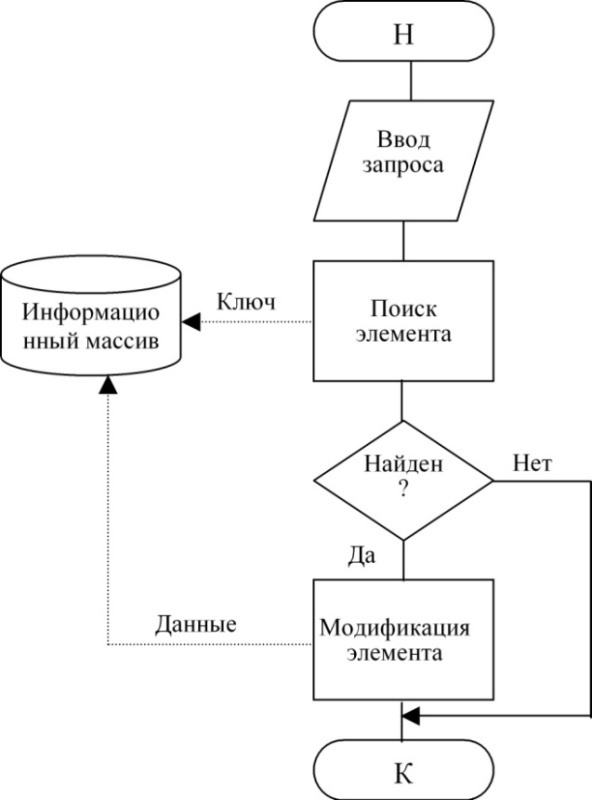
Рисунок 79. Технологии доступа при выполнении действий изменения элемента
Технологии доступа при выполнении действий добавления элемента показаны на рис. 80:
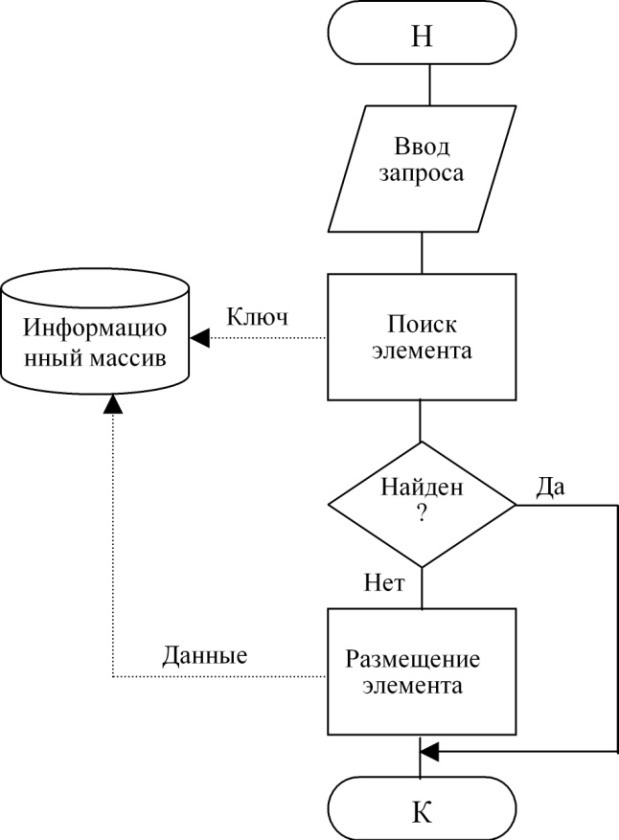
Рисунок 80. Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рис. 81.
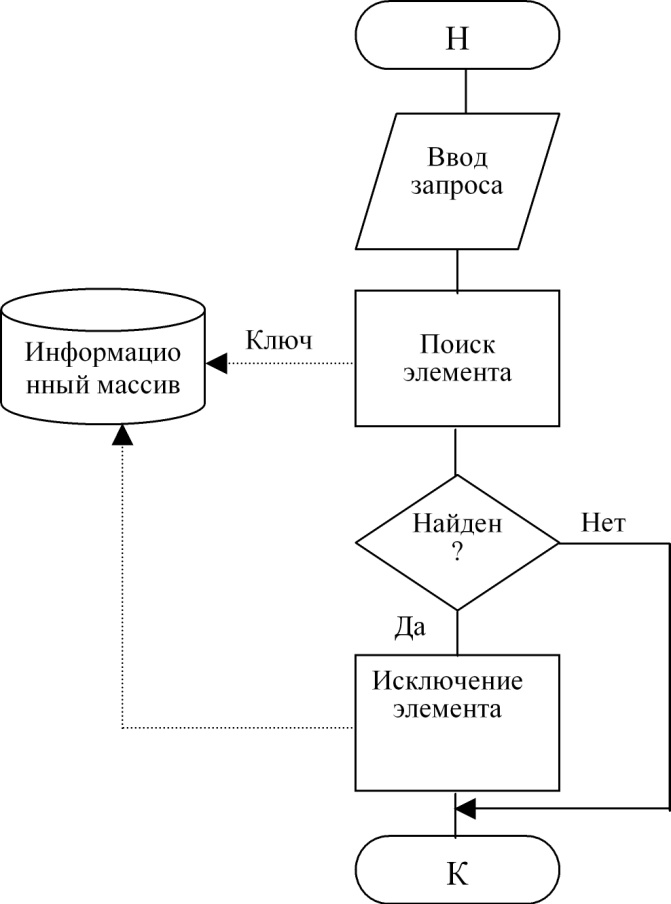
Рисунок 81. Технология удаления элемента
Технология просмотра элемента приведена на рис. 82. Различие в схемах состоит в том, что по технологии рис. 79 и 80 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рис. 81 воздействие не связано с передачей данных, а по схеме рис. 82 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
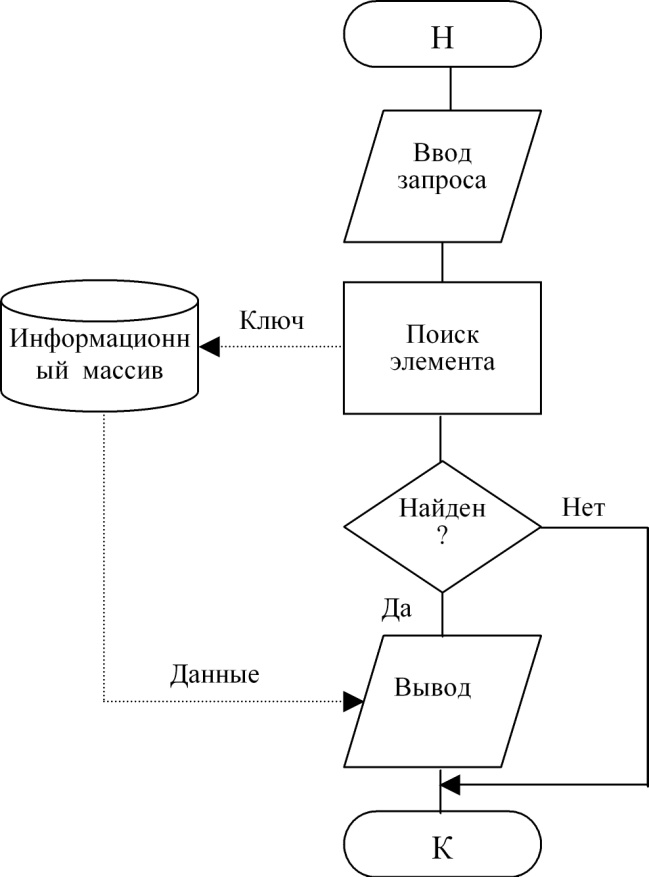
Рисунок 82. Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения.
Излагаемые модели данных и алгоритмы доступа к ним составляют “brainware” современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, устанавливающим, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, который может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как описано выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.


