Работа с данными
В процессе анализа неструктурированных данных мы проходим несколько шагов:
Рассмотрим подробнее каждые этапы.
Шаг 1. Формулировка вопроса помогает: определить какие данные нужны, придерживаться выбранного направления анализа, снизить риск отклонения от поставленной цели. Ошибка, допущенная на первом этапе, может привести к потере времени и «обнулить» результат работы всей команды.
Шаг 2. Подготовка данных практически всегда является сложным и трудоемким процессом, т.к. требует извлечения данных из исходных источников, их преобразования для работы и очистки от «грязных» данных. Мы извлекаем данные с web-сайтов, социальных сетей, из готовых баз данных, CSV-файлов, таблиц Excel. Подготовленные данные должны быть правильно отформатированы, учтены все отклонения (например, чрезмерно отклоняющиеся данные).
Для работы с данными мы используем инструмент Python, а именно, некоторые методы, которые могут применять в работе не только IT специалисты, но и аудиторы, делающие только первые шаги в программировании на этом языке.
Например, в наших выборках мы часто встречаем пропущенные значения. Пропуски могут возникать в результате объединения двух файлов с данными, в которых названия меток индексов и столбцов не совпадают, или значение переменной нам в данный момент неизвестно, или данные, полученные с внешних сайтов — неполные.
Для поиска пропусков в значениях (значения NaN в объекте DataFrame) мы используем библиотечный метод. isnull(). Значение «True» в наших данных после применения. isnull() означает, что в этой позиции элемент NaN.
Чтобы определить, что элемент не является пропущенным значением можно применить. notnull().
Чтобы вычислить количество NaN, мы используем метод. sum(), который принимает значение True =1, False=0.
Кроме того, можно воспользоваться методом. count(): для объекта Series метод возвращает число непропущенных значений. Для DataFrame считает количество непропущенных значений в каждом столбце.
Также для обработки пропущенных данных мы используем простое их удаление из нашей выборки. В библиотеке Pandas есть для этого несколько методов. Один из них — это фильтрация по условию с использование результатов ранее примененных. isnull() и. notnull(). Например, чтобы отобрать в столбце 3 нашей DataFrame (df) непропущенные значения используем код: df.c3[df.c3.notnull()], который извлечет все значения столбца 3, кроме NaN. Кроме того, мы используем метод. dropna(), который удаляет из объекта DataFrame строки, содержащие значения NaN. Для удаления только строк, в которых все значения неопределенны, используем параметр how = ‘all’: df.dropna(how=’all’). C помощью параметра how = ‘any’, удаляем столбцы, где есть хотя бы одно значение NaN. А с помощью параметра thresh задаем необходимый минимум заполненных значений, для того чтобы не удалять строки столбцы, в которых есть пропуски.
В некоторых случаях пропущенные значения мы заполняем определенным значением, используя метод. fillna(). Пропущенные значения можно заполнить константой, или последним непропущенным значением как в прямом:. fillna(method = «ffill”), так и обратном порядке:. fillna(method = ‘bfill»). Или заполняем с помощью индексов: fill_values. Кроме того, мы применяем метод интерполяции пропущенных значений. interpolate().
Шаг 3. Анализ подготовленных данных мы осуществляем с помощью методов классификации, кластеризации и обучения с подкреплением.
Каждый из этих инструментов мы используем в следующих случаях:
— метод классификации, если нами заранее определено в какие группы будем объединять данные (ответы «да»/«нет»);
— метод кластеризации, когда группы заранее неизвестны. Например, будем делать оценку возрастной категории клиента, давшего тот или иной ответ;
— метод обучения с подкреплением, когда не требуется выполнять точно заданные действия, но можно проводить исследования и обучаться лучшим методам решения задач.
Шаг 4. Переходя к визуализации данных, мы используем «две стороны одной монеты»: с одной стороны, мы визуализируем данные, чтобы изучить их, а с другой представить окружающим наши выводы и гипотезы. Визуальный анализ на этапе обработки данных помогает увидеть аномалии в данных, сделать обобщения результатов, выявить тенденции поведения групп данных и проверить отвечают ли наши данные на изначально заданный вопрос. Для этого мы используем пакет Seaborn для программ Python и ggplot2, и Shiny для R.
Визуализация данных для презентации результатов окружающим осуществляется с помощью программ PowerBI и Tableau. Данный этап также совмещает в себе подготовку выводов.
Подводя итог, хочется сказать, что часто методы работы с данными, освоенные ранее и которые нам нравятся, могут оказаться неэффективными. Привыкнув работать с Excel, не нужно бояться осваивать языки программирования Python или R. Ведь использование указанных выше программных продуктов помогают значительно ускорить процесс обработки данных.
ЦП Автоматизированные системы управления и промышленная безопасность
БК Автоматизированные системы управления и кибернетика
35. Основные операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
• сбор — накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация — приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация — отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка — упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
• архивация — организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита — комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой.
Технологии доступа при выполнении действий изменения элемента показана на рис. 79.
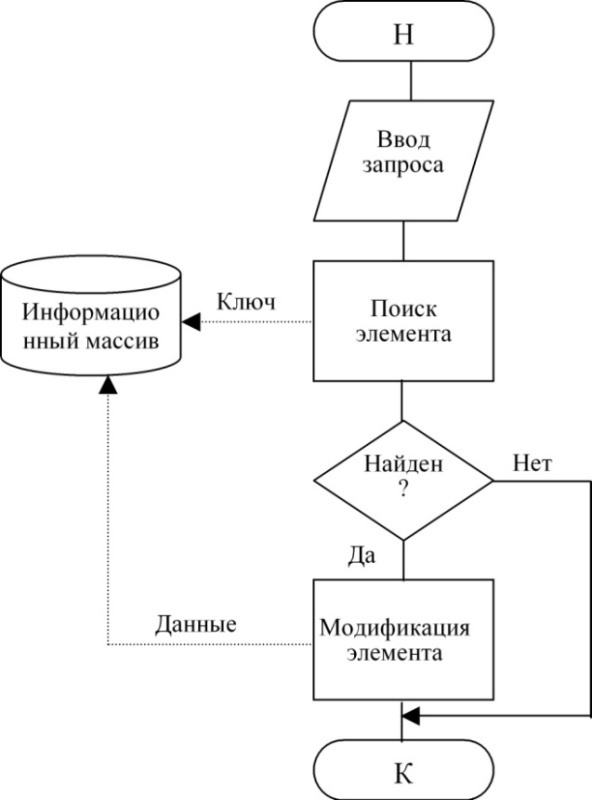
Рисунок 79. Технологии доступа при выполнении действий изменения элемента
Технологии доступа при выполнении действий добавления элемента показаны на рис. 80:
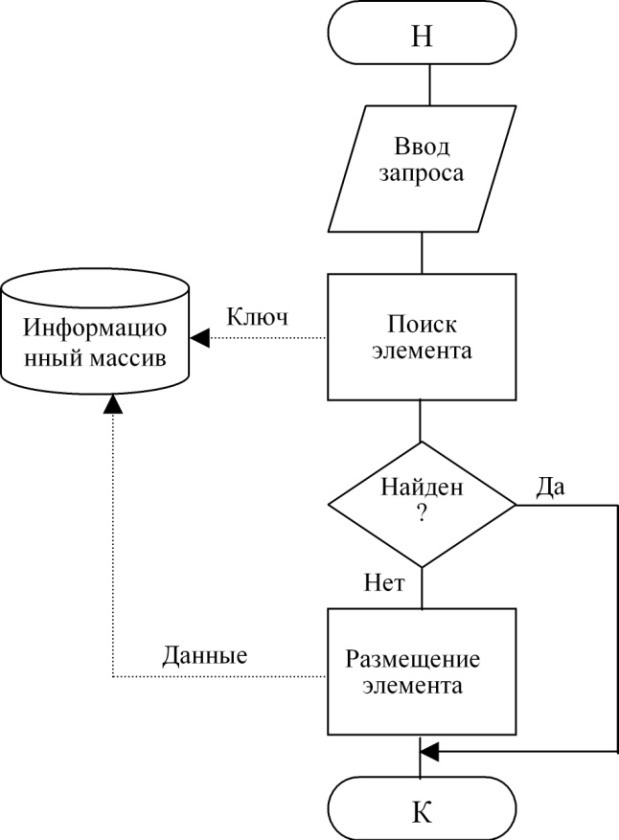
Рисунок 80. Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рис. 81.
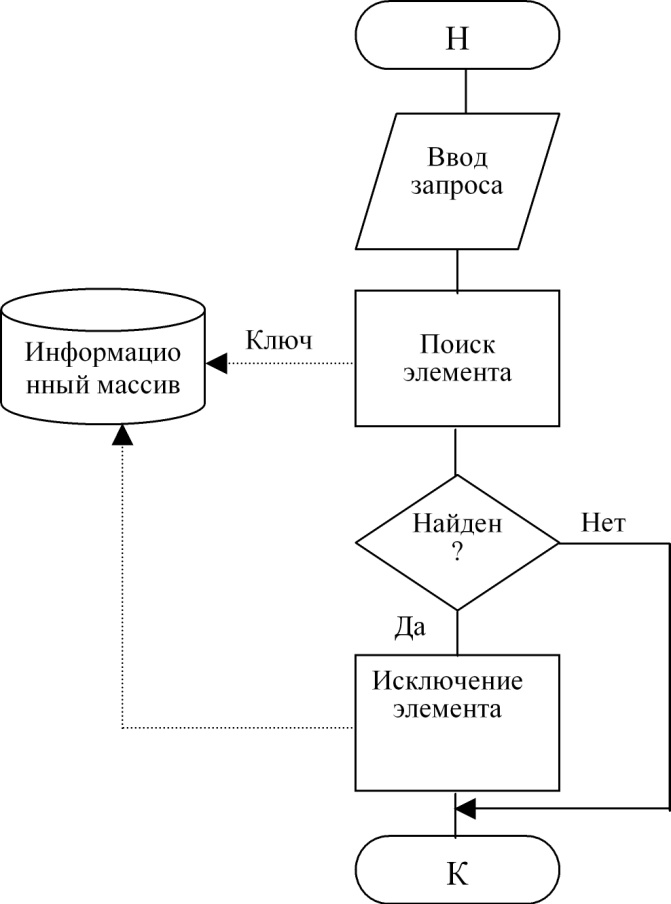
Рисунок 81. Технология удаления элемента
Технология просмотра элемента приведена на рис. 82. Различие в схемах состоит в том, что по технологии рис. 79 и 80 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рис. 81 воздействие не связано с передачей данных, а по схеме рис. 82 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
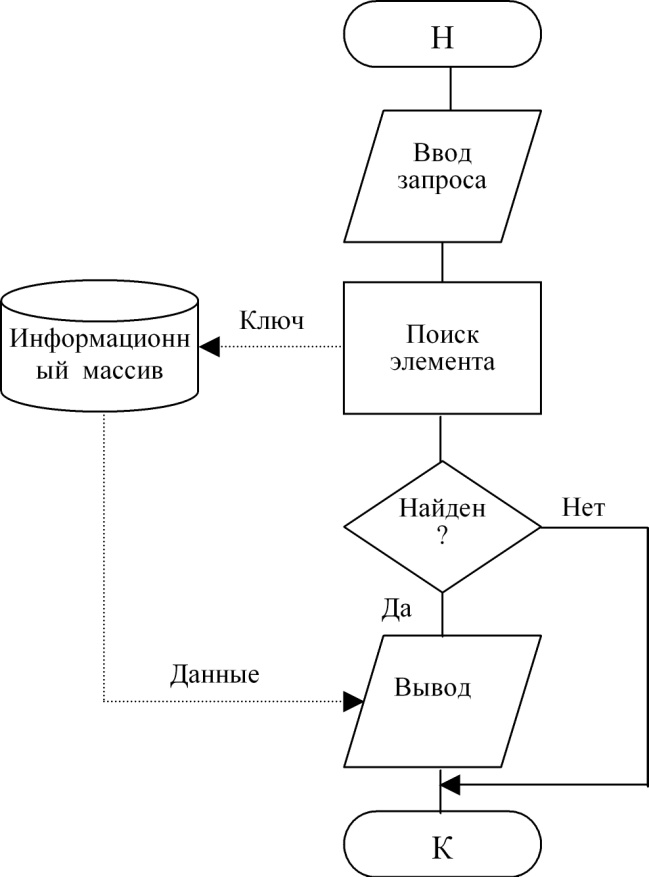
Рисунок 82. Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения.
Излагаемые модели данных и алгоритмы доступа к ним составляют “brainware” современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, устанавливающим, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, который может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как описано выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
Персональные данные сотрудника: как с ними работать

Неоднозначное понимание того, что именно скрывается под персональными данными, в итоге приводит к конфликту между сторонами, когда работодатель и работник злоупотребляют своими правами. Чтобы избежать таких ситуаций, надо понимать, как правильно обрабатывать персональные данные на каждом этапе взаимодействия.
Основные документы, на которые нужно ориентироваться при обработке персональных данных, — это Конституция РФ (ст. 24) и Федеральный закон от 27.07.2006 № 152-ФЗ (далее — Закон о персональных данных).
В ст. 24 Конституции РФ говорится, что «сбор, хранение, использование и распространение информации о частной жизни лица без его согласия не допускаются». Закон о персональных данных определяет значение не только ключевых понятий, с которыми придется сталкиваться на практике каждому работодателю, но и вводит принципы и условия обработки персональных данных, права субъекта персональных данных и другие важные моменты.
Вопросам защиты персональных данных работника посвящена гл. 14 ТК РФ.
Что включают персональные данные работника
Персональные данные — это любая информация, относящаяся к прямо или косвенно определенному физическому лицу (субъекту персональных данных). Как правило, эти данные позволяют идентифицировать конкретного человека.
В рамках трудовых отношений работодатель может запрашивать только те персональные данные, которые нужны для выполнения трудовой функции. К ним относятся ФИО, сведения о предыдущей работе, документы, которые необходимы для устройства на работу (паспорт, трудовая книжка и т.д.), сведения об образовании. Такие сведения, как вероисповедание, работодатель запрашивать не имеет права, так как они не требуются для выполнения трудовой функции.
Сложность обработки персональных данных заключается в том, что на разных этапах взаимодействия и при решении различных трудовых задач у работодателя могут возникнуть вопросы. Например, считается ли та информация, которая содержится в резюме кандидата, персональными данными? Должен ли он давать согласие в этом случае, даже если его не возьмут на работу? Нужно ли как-то согласовывать с работником факт передачи данных для оформления пропуска? Можно ли размещать фотографию работника на доске почета без его согласия? Допускается ли размещение «черных списков» сотрудников на сайте компании? Что делать с данными уволенных сотрудников?
На все эти вопросы важно знать ответы. Тем более что периодически разъяснения по ним публикуют Минтруд, Роструд, Роскомнадзор.
Что делать с персональными данными кандидата
Еще на этапе просмотра резюме компания начинает собирать персональные данные кандидатов. Она может сохранять резюме в специальных программах, распечатывать их, сохранять контакты для дальнейшей связи и т.д.
В резюме обычно представлен целый перечень персональных данных — от номера телефона до сведений об образовании и предыдущих местах работы.
Роскомнадзор предупреждает о том, что обработка персональных данных соискателей предполагает получение соответствующего согласия от них. Согласие следует оформлять на период принятия решения о приеме либо отказе в приеме на работу.
Но есть и исключения, когда такое согласие не требуется:
В согласии нужно обязательно указать цель получения персональных данных — рассмотрение кандидата на вакантную должность. Можно воспользоваться образцом согласия на обработку персональных данных.
Если работодатель получает резюме соискателя по электронной почте, ему нужно дополнительно провести мероприятия, которые бы служили подтверждением факта направления резюме самим соискателем. Например, это может быть приглашение соискателя на собеседование или ответ на его письмо по электронной почте.
Что делать, если персональные данные собираются с помощью анкеты
Нередко работодатель осуществляет сбор персональных данных кандидатов с помощью типовой анкеты. Во-первых, такая анкета должна содержать информацию о сроке её рассмотрения и принятия решения о приеме либо отказе в приеме на работу.
Обычно анкета размещается в электронном виде на сайте компании, и согласие на обработку персональных данных подтверждается с помощью проставления «галочки» в соответствующем поле.
Что делать с данными кандидата, которого не взяли на работу
В таком случае предоставленные соискателем данные нужно уничтожить в течение 30 дней.
Есть в этой ситуации исключения — случаи, предусмотренные законодательством о государственной гражданской службе. Тогда хранить персональные данные соискателя придется в течение 3-х лет.
Направление запросов на прежние места работы
На этапе собеседования работодателю может потребоваться уточнение некоторых данных о работнике или получение дополнительной информации у прежних работодателей.
Для этого ему обязательно нужно заручиться согласием соискателя.
Сбор и обработка персональных данных при приеме на работу
Трудовое законодательство определяет перечень документов, которые работодатель запрашивает у работника при приеме на работу. На этом этапе, согласно ст. 65 ТК РФ, запрашиваются:
На то, чтобы внести персональные данные из этих документов в трудовой договор, согласие работника не требуется. Когда он подписывает трудовой договор, то тем самым уже дает свое согласие.
Оформление зарплатной карты и персональные данные работника
Многие организации при приеме на работу оформляют работникам зарплатную карту. В связи с этим может возникнуть вопрос — нужно ли на передачу персональных данных работника банку получать согласие? Да, нужно.
При этом важно, чтобы:
Роскомнадзор определяет случаи, когда передача персональных данных работника банку для открытия зарплатных карт должна происходить без согласия:
Стоит учесть, что работник может отказаться подписать согласие на передачу данных банку, с которым работает компания. У него могут быть уже открыты счета и карты в другом банке, и поэтому для него удобнее продолжать обслуживаться в своем банке.
В прошлом году была установлена ответственность за «зарплатное рабство». Это значит, что сотруднику нельзя отказать в праве на изменение кредитной организации, в которую будет перечисляться зарплата.
Сотрудник сменил фамилию — что делать с трудовым договором?
В этом случае нужно обязательно внести изменения в трудовой договор. Главное — сделать это правильно.
Часто работодатели оформляют дополнительное соглашение, хотя им, как правило, меняются условия, а не сведения трудового договора. Фамилия относится именно к сведениям о работнике.
Правильно будет внести изменение непосредственно в текст трудового договора, вручную.
Размещение «черных списков» сотрудников на сайте
Иногда работодатель смело публикует в открытом доступе списки бывших работников, которые были уволены, например за утрату доверия или неоднократное неисполнение обязанностей.
Следует отметить, что это расценивается законом, как нарушение требований к обработке персональных данных. Об этом, в частности, предупреждает Минтруд в Письме от 08.10.2018 N 14-2/В-803.
В данном случае, публикуя причины увольнения, работодатель сообщает личную информацию сотрудника третьим лицам. Делать это без согласия работника нельзя.
Каким должно быть согласие на обработку персональных данных
Роскомнадзор в своих рекомендациях формулирует следующие требования:
Оформление доски почета
Противоположная ситуация — это поощрение работника в виде доски почета. Но и здесь есть свои тонкости.
Обычно на доске почета размещается фотография человека, указывается его ФИО. И всё это персональные данные, которые работодатель не имеет права выставлять на всеобщее обозрение у себя в офисе, даже если цель его действий — поощрить успешных сотрудников и мотивировать тем самым остальной коллектив.
Для использования фото сотрудника тоже придется заручиться согласием.
Персональные данные для пропуска
В большинстве организаций сейчас действует пропускной режим. Соответственно, новым работникам требуется оформление пропуска.
В данном случае нет необходимости в получении согласия на обработку персональных данных, если:
В том случае, если пропускной режим находится под контролем сторонней организации, то согласие обязательно.
Кадровый и бухгалтерский учет на аутсорсе и персональные данные
Если работодатель решает вопросы кадрового и бухгалтерского характера при помощи аутсорса, то есть силами сторонних организаций, то он должен соблюдать требования, обозначенные ч. 3 ст. 6 Закона о персональных данных.
Что делать с персональными данными уволенных сотрудников
Нужно учитывать, что существуют требования к обработке персональных данных в рамках бухгалтерского и налогового учета.
Так, например, работодатели обязаны в течение 4-х лет обеспечивать сохранность документов, необходимых для исчисления, удержания и перечисления налога (пп. 5 п. 3 ст. 24 НК РФ). И здесь согласия уже бывших сотрудников, хотят они того или нет, не требуется.
Роскомнадзор напоминает, что по истечении сроков, определенных законодательством, личные дела работников переходят на архивное хранение на срок 75 лет. Но на саму организацию хранения в архиве и использование архивных документов с персональными данными работников Закон о персональных данных не распространяется.
Не пропустите новые публикации
Подпишитесь на рассылку, и мы поможем вам разобраться в требованиях законодательства, подскажем, что делать в спорных ситуациях, и научим больше зарабатывать.
10 вещей, которые сможет сделать мошенник, завладевший данными вашего паспорта
Однажды человека может разбудить неожиданный звонок с требованием вернуть долг, а в почтовом ящике окажется повестка в суд. Но кредитов он не брал, закон не нарушал — возможно, кто-то наживается на его паспортных данных.
Вот как могут подставить мошенники, заполучив информацию из паспорта.
Взять микрокредит
Чтобы взять кредит в крупном банке, одних паспортных данных недостаточно: потребуется хотя бы копия документа.
А вот оформить микрозаем в интернете можно с помощью сведений с первых страниц паспорта — номера, даты выдачи, кода подразделения и места рождения.
Обратившись в несколько микрофинансовых организаций, мошенники получат существенную сумму на свои карты — а затем исчезнут, оставив жертву с долгами.
Зарегистрировать фирму
Пользуясь данными чужого паспорта, мошенники регистрируют фирму-однодневку. Так они безнаказанно творят темные дела: уклоняются от налогов или собирают с обычных людей деньги за предзаказ дорогих товаров.
Оформить рассрочку
Некоторые интернет-магазины предлагают клиентам покупать товары в рассрочку: чтобы забрать вещь, нужно указать паспортные данные, а оплатить покупку можно позже.
Это на руку мошенникам: они заказывают товар по чужому документу, а курьеру говорят, что покупку получит другой человек — не владелец паспорта. Предупрежденный курьер спокойно отдает дорогую вещь аферисту, но расплачиваться за нее должен ничего не подозревающий владелец паспорта.
Прислать квитанцию
Зная ФИО жертвы и адрес регистрации, мошенники подделывают квитанции на оплату штрафов от государственных органов.
Чтобы оплатить «штраф» и избежать суда, аферисты просят как можно скорее воспользоваться вложенной квитанцией.
Зарегистрировать электронный кошелек
Мошенники, которые обманывают людей в интернете, часто просят жертв выслать им деньги на электронный кошелек — поэтому аферистам выгодно использовать чужие данные. Так вся ответственность за мошенничество ляжет на плечи подставного владельца кошелька, а настоящие преступники останутся незамеченными.
Подделать паспорт
Притвориться полицейским
Мошенник предлагает «выкупить» родственника, попавшего в беду: якобы ребенка доставили в отдел полиции, потому что он сделал что-то противозаконное. Этот обман распространен и многие о нем знают, поэтому лжеполицейский прикрывается персональными данными жертвы: называет точный возраст и имя ребенка, а еще данные паспорта родителя, которые «пробил» по полицейской базе.
Выяснить номер телефона по паспортным данным несложно. Многие указывают его на страницах в соцсетях или на страницах-визитках, которые можно найти, просто набрав имя и фамилию жертвы в поисковике.
Обманывать на сайтах объявлений
Мошенник размещает объявление о продаже дорогой вещи по бросовой цене: утверждает, что надо продать срочно, поэтому и скидка большая. А так как цена привлекательная, то и желающих много, поэтому аферист настаивает на предоплате: чтобы не терять время, если покупатель вдруг передумает.
В качестве гарантии липовый продавец высылает скан паспорта — разумеется, чужого, а после получения денег перестает отвечать на сообщения.
Шантажировать
Заполучив чужие паспортные данные, мошенники находят владельца паспорта в соцсетях и предлагают заплатить им за удаление информации о документе, а иначе обещают оформить микрозаймы на имя жертвы.
Из тех, кто согласится, мошенники вытягивают все более крупные суммы, шантажируя новыми махинациями. Если жертва отказывается платить, аферисты присылают сообщение с другого аккаунта, притворяясь обманутым покупателем с сайта объявлений: мол, знаю ваши паспортные данные, если не возместите ущерб — обращусь в полицию.
Оформить симкарту
Если сотрудник посчитает копию верной, мошенник сможет оформить симку на чужие данные. Это поможет преступнику обманывать людей по телефону, не боясь полиции, — в случае чего оператор выдаст паспортные данные жертвы.
С помощью симкарты мошенники тоже могут взять кредит, оставив должником владельца настоящего паспорта: некоторые операторы связи позволяют клиентам оформить через интернет банковскую карту с кредитным лимитом
Мошенничество по телефону


