Как проверить правильность (валидность) готового HTML-кода
Берём валидатор, подключаем хинтер и запасаемся терпением… Главное, не перепутать последовательность!


Если вдруг вы задавались вопросом: «Как проверить, правильный (валидный) ли у меня HTML-код?» — эта статья для вас. Разберёмся, зачем вообще нужен валидный код, на что он влияет и почему это важно.
Зачем нужна валидация кода
Правильный, валидный html-код — это код, написанный по спецификации W3C, в которой собраны стандарты и рекомендации по удобству и универсальности Всемирной сети.
При написании кода стоит придерживаться этих правил. Они в целом довольно похожи на правила обычного, привычного нам русского языка. Например, если вы не закроете тег (в русском языке — не закончите правильно абзац текста) — будет нарушена структура и смысловая составляющая. Проверка кода на валидность позволяет увидеть все подобные ошибки и исправить их.
Но конечно, дело не только в структуре. Ваш код могут смотреть как другие разработчики, так и браузер, а также поисковые машины. И чтобы страница быстрее загружалась, правильнее обрабатывалась, а поисковые машины верно понимали смысл всех тегов, важно писать валидный код.

Автор статей по программированию. Преподаватель, ментор, выпускник Skillbox. Фрилансер, веб-разработчик
Валидатор
Для того чтобы быстро, удобно и в автоматическом режиме проверять свой код, существует помощник — валидатор W3C. Он используется повсеместно (хотя есть и другие), так как придуман и написан консорциумом W3C — теми, кто создал и поддерживает стандарт языка.
Как им пользоваться? Давайте посмотрим на примере простого HTML-фрагмента.
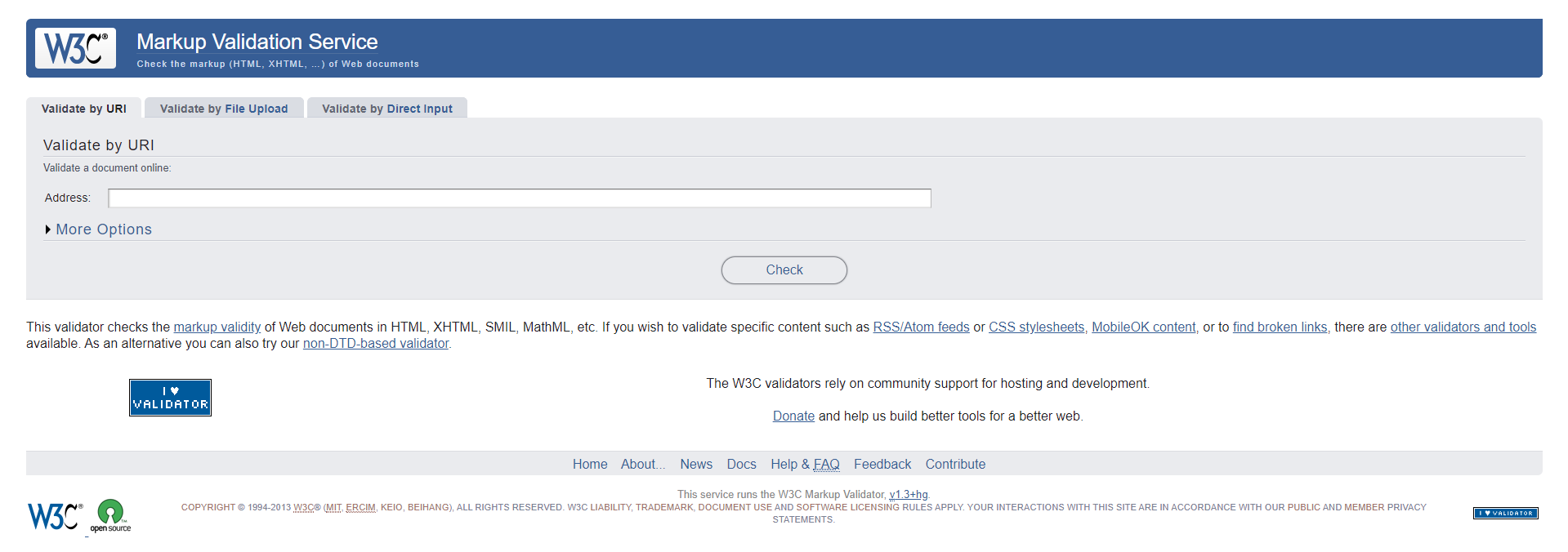
Валидатор позволяет выбрать, в каком именно виде вы передадите ему информацию: по ссылке на сайт из интернета, загрузите файл или же просто скопируете и вставите код в специальное поле.
Если ваш сайт пока ещё не выложен на хостинг, оптимальным вариантом будет вставка кода. Если же уже на нём — выбирайте первый вариант, по ссылке.
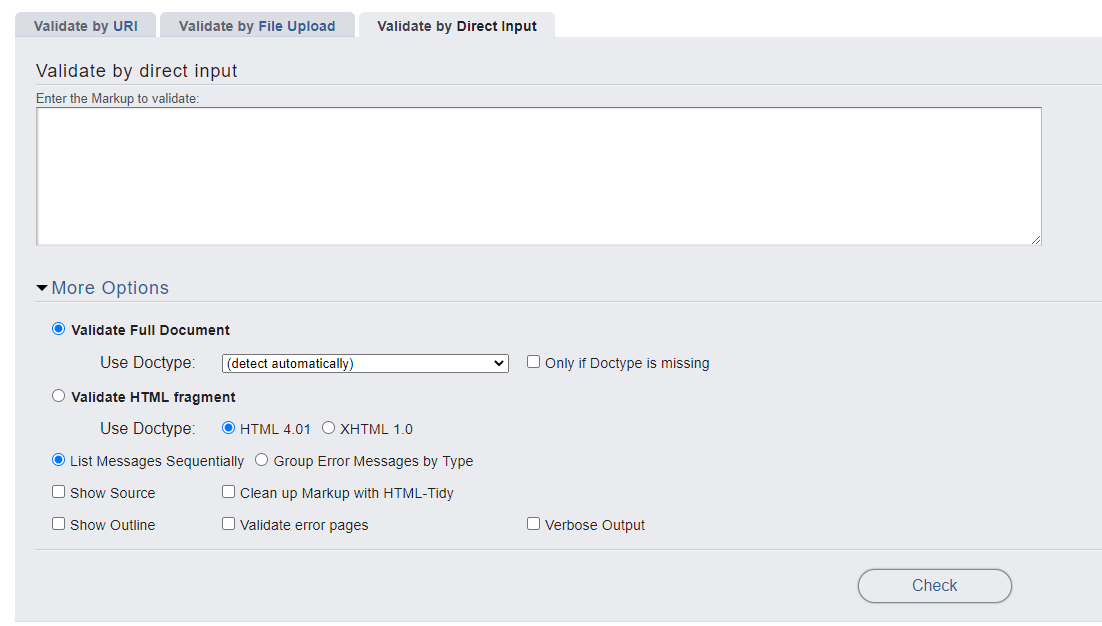
Попробуем вставить некий код в поле для ввода.
Теперь, когда код вставлен, остается лишь нажать check. У валидатора есть ещё и другие настройки: выбор версии языка HTML (за который и так отвечает DOCTYPE), а также группировка ошибок по типу.
Что именно проверяет валидатор?
Валидатор оценивает синтаксическую составляющую кода: смотрит на пропущенные или ошибочные теги, проверяет, верно ли вы закрыли тот или иной блок кода.
Результаты, выданные валидатором, делятся на две категории: предупреждения и ошибки. В нашем варианте кода как раз есть и те и другие.
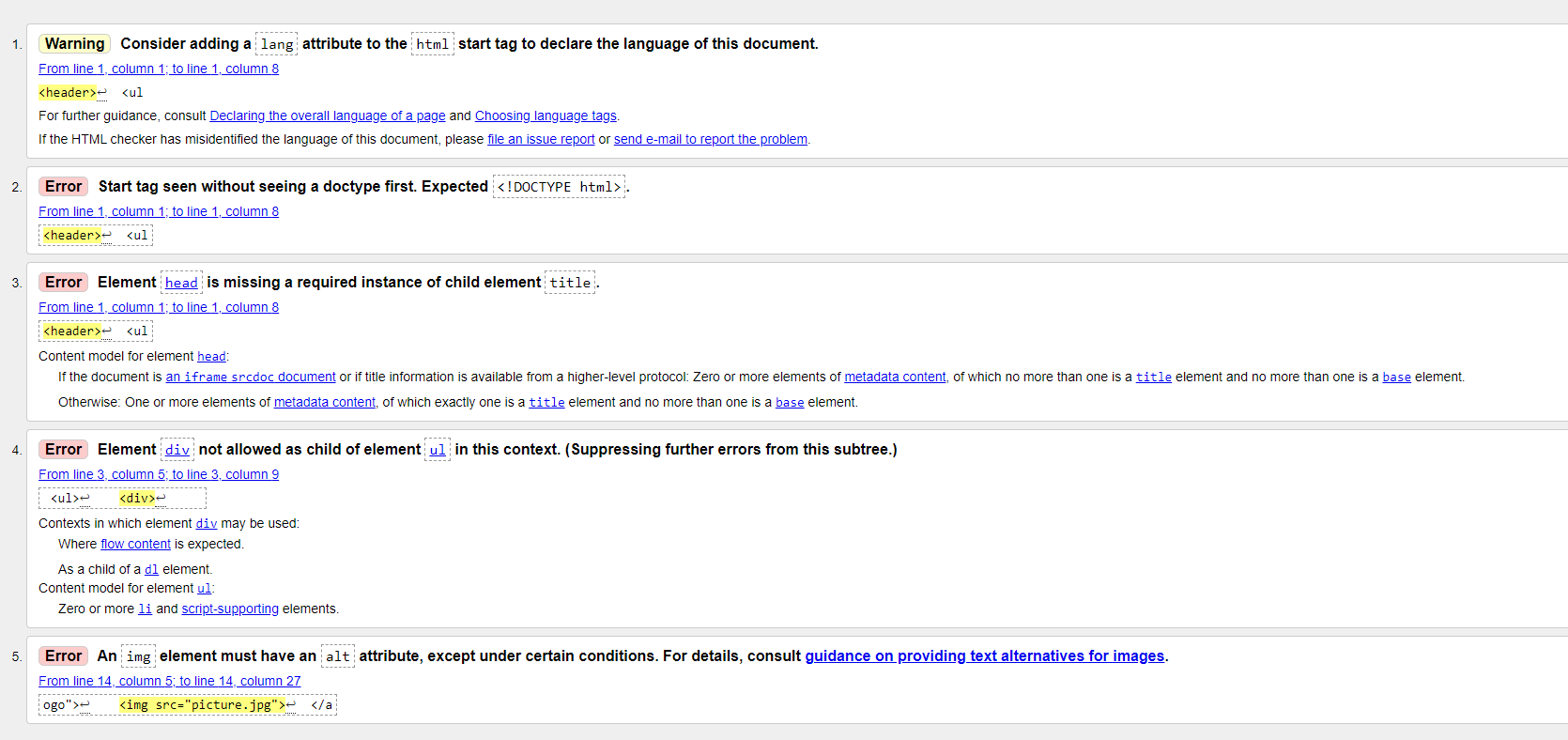
Предупреждения — это какие-то незначительные неточности в коде, которые не сломают сайт, но не соответствуют стандартам кода.
Ошибки — более серьёзные проблемы, которые могут повлиять на работу кода в целом. Это могут быть как грубые ошибки — например, неверная вставка тега в тег, неверное закрытие тега и т.д., так и менее значимые — отсутствие атрибута alt, незаполненный тег title.
Рекомендация: просто исправлять всё, что там есть, чтобы осталось лишь заветное зелёное уведомление о том, что всё правильно. Правильность кода — залог его корректной и долговечной работы, а также плюс при работе в команде с другими верстальщиками\backend-разработчиками.
Как ещё можно проверять верстку
Помимо классического валидатора есть ещё один тип инструментов — так называемые хинтеры. Как правило, это плагины для редакторов кода, которые при написании кода автоматически подчеркивают ошибки и указывают, что нужно исправить. Один из таких плагинов — HTMLHint для редактора VS Code.
Хинтер работает по определённым правилам, которые довольно схожи с правилами валидатора. Но в идеале стоит проверять верстку как хинтером, так и валидатором, чтобы точно всё исправить.
Со списком правил хинтера можно ознакомиться по ссылке.
Правильный HTML-код крайне важен. Стандарты языка придуманы не просто так. Даже если ошибка кажется несущественной, она может повлиять на логическую сторону кода (например, отсутствие alt — описания изображения).
Всегда проверяйте свой код, обращайте внимание на частые ошибки, чтобы в будущем их не совершать. Научиться профессионально создавать сайты и писать валидный html можно на курсе по веб-вёрстке.
Как проверить валидность HTML-разметки

Если вы хотите узнать, что такое валидный код, то вы попали на нужную страницу. Разберёмся, что значит сам термин, как работает валидатор и почему это важно.
Что это и зачем
Валидный HTML-код, валидная разметка — это HTML-код, который написан в соответствии с определёнными стандартами. Их разработал Консорциум Всемирной Паутины — World Wide Web Consortium (W3C). Что именно это значит?
Писать код — это примерно как писать какой угодно текст, например, на русском языке. Можно написать понятно, вдобавок грамотно, а также разбить текст на абзацы, добавить подзаголовки и списки. Так и с валидностью кода. Если вы создаёте разметку, которая решает ваши задачи корректно, то для того, чтобы ваша работа была валидной, в ней стоит навести порядок.
Понятный код — меньше хлопот
Для чего это нужно? Иногда нам кажется, что другие думают как мы. Что не надо стараться объяснять. Но вот нет. Чтобы другие поняли вас быстрее, надо учитывать правила передачи информации. Под другими можно иметь в виду коллегу по команде, а также браузер или компилятор — любое ПО, которое будет работать с вашей разметкой.
Валидность кода определяет то, как будет выглядеть страница или веб-приложение в разных браузерах и на различных операционных платформах. Валидный код по большей части во многих браузерах отображается предсказуемо. Он загружается быстрее невалидного. Валидность влияет на восприятие страниц и сайтов поисковыми системами.
Спецификации кода могут быть разными. Нет универсальной в такой же степени, как и нет абсолютно правильного кода, который работает на всех устройствах и программах правильно. Хотя, сферический вакуумный конь поспорил бы с этим.
Валидатор — это.
Так же, как и с проверкой грамотности языка, HTML-код можно проверять вручную — своими глазами и мозгами, а можно пользоваться и автоматическими помощниками. Это может быть отдельный целостный сервис, а может быть дополнение к браузеру. Первое лучше. Инструменты валидации HTML-кода онлайн облегчают жизнь разработчика, которому не нужно самому вычислять, например, парность скобок.
Как пользоваться валидатором
Рассказываем на примере «родного» валидатора W3C. Этот валидатор используется потому, что его сделали авторы правил, которым должен соответствовать код. Вы можете пройти по ссылке и провести валидацию кода на своём любимом сайте. Будет интересно.
За вами выбор способа проверки. Можно проверять код по ссылке, можно загрузить в сервис HTML-файл, а можно фрагмент кода. В третьем варианте как раз и идёт речь о написанном в окне сервиса коде или скопированной части из разметки всей страницы.
Цепочка действий в два шага. Первый — предоставить исходный код, а второй — нажать на кнопку проверки.
Вы можете пойти дальше и задать дополнительные параметры валидации. Они нужны, чтобы структурировать и детализировать результаты.
Интерпретация результатов валидации
Инструмент валидации оценивает синтаксис, находит синтаксические ошибки типа пропущенных символов и ошибочных тегов и т.д. И отлавливает одну из частых ошибок вложенности тегов.
Часто в результате сервисы валидации разметки, как и компиляторы в разработке, выдают список, разделённый на предупреждения и ошибки. Разница в критичности. Ошибки с максимальной вероятностью могут создать проблемы в работе кода. Это опечатки (да, техника любит точность), лишние или недостающие знаки. А вот к предупреждениям относятся неточности, которые с минимальной вероятностью навредят работе страницы, но не соответствуют стандартам. Это избыточный код, бессмысленные элементы и другие «помарки».
Так выглядит результат валидации HTML-кода на очень простой странице, созданной за пару часов в конструкторе сайтов.
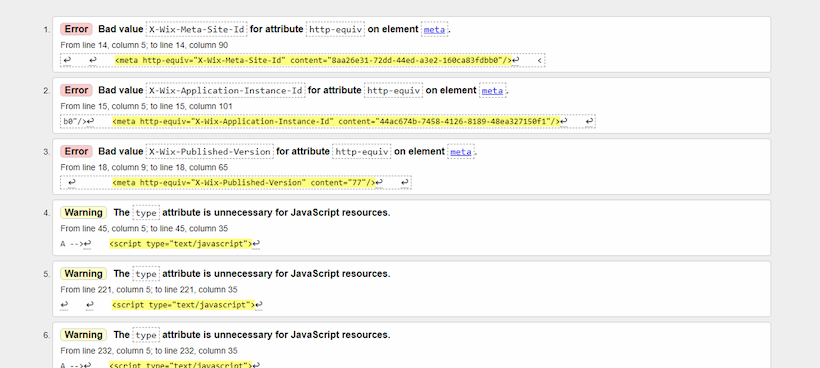
Ошибки и предупреждения собраны в список. В каждом элементе списка указаны значение, атрибут и элемент, которые не устроили валидатор, а также приведена цитата кода с ошибкой.
Сами валидаторы могут ошибаться. То, что не пропускает валидатор, может быть корректно обработано браузером. Так что не обязательно исправлять абсолютно все ошибки в своей разметке. Обращать внимание и уделять время проверке надо при серьёзных ошибках, которые мешают корректной работе сайта и отображению страниц.
Подробнее о валидаторе, правилах построения HTML-разметки, а также другие интересные и важные вещи мы разбираем на интенсивных курсах.
Список на память
Валидный код — гордость верстальщика
Пройдите курсы по вёрстке, чтобы вами гордились все знакомые. 11 глав по HTML, CSS и JavaScript бесплатно.
Нажатие на кнопку — согласие на обработку персональных данных
Обсуждение статьи, вопросы авторам, опечатки и предложения — в телеграм-чате HTML Academy.
Валидность сайта и её проверка
Страницы всех сайтов в интернете оформляются специальным кодом, прописанным по стандартизированным правилам HTML.

Что такое валидность?
Валидация — это проверка на соблюдение установленных норм, а в контексте, применяемом вебмастерами — корректности кода страниц: синтаксических ошибок, вложенности тэгов и т. п. Если все делать «правильно», код страницы не должен содержать неверные атрибуты, конструкции и ошибки. Валидация сайта позволяет выявить недостатки, которые следует исправить.
Выяснить, есть ли замечания или ошибки в коде веб-страницы, можно как онлайн, так и не имея доступа к Сети и пользуясь оффлайн-программами.
Что такое валидаторы кода
Валидатор кода — это программа, используя которую можно проверить HTML-код страниц и CSS-код на соответствие современным нормам. Она находит и фиксирует некорректные элементы, указывая на их местонахождение и формулируя, что именно оформлено неверно.
Основные «приметы» валидной верстки
Валидная вёрстка содержит код, полностью соответствующий требованиям W3C (World Wide Web Consortium), занимающейся разработкой технологических стандартов для всего Интернета.
Если код на страницах сайта верный, то во всех браузерах сайт отображается корректно (а не криво).
Отсутствуют подозрения о несправедливом «понижении» в выдаче и нет страниц, выкинутых из индекса.
Пример. Если, предположим, неправильно стоят теги
, (в частности, отсутствует закрывающий элемент), то поисковик не будет ничего исправлять — он будет интерпретировать так, как написано черным по белому в коде. В итоге могут возникнуть последствия, связанные уже с продвижением сайта.
Важна ли валидная верстка в продвижении сайта
В теории да, но на практике оказывается, что в топе висит множество сайтов с ошибками валидации, да и сайты с ошибками двигаются в общем неплохо. Проблемы с продвижением могут быть только если ваш сайт некорректно отображается на каком-то типе устройств или в каком-то браузере. Если же он выглядит отлично, но ошибки в валидации есть — на продвижение это не окажет никакого влияния.
Некоторые вебмастера целенаправленно исследовали этот вопрос, пытаясь выяснить, зависят ли результаты ранжирования от результатов валидации. Вебмастер Марк Даост отметил, что валидность кода не принципиальна. А Шаун Андерсон, напротив, пришел к выводу, что валидность как бальзам на душу сайту в плане позиций выдачи.
Еще один специалист, Майк Дэвидсон, также провел подобный эксперимент и пришел к выводу, что Google классифицирует страницы по качеству их написания. Например, незакрытый тег может привести к восприятию части контента как значение этого тега.
Этот вебмастер сделал очень важный вывод:
Зачем нужен валидный код
Валидный код позволяет правильно отображать страницы в браузерах (и стили для сайта CSS могут быть отображены неверно).
Причем вполне возможна ситуация, когда в одном браузере ваш сайт отображается так, как вы его настроили, а в другом — совершенно иначе. Изображение может быть перекошено, а контент может стать совершенно нечитабельным.
В итоге вы теряете трафик из этого браузера. К тому же, поведенческий фактор, являющийся одним из трёх самых важных факторов в SEO, значительно влияет на результаты выдачи.
Представьте, что на ваш сайт заходят посетители и тут же его закрывают из-за невозможности воспринять информацию — спасибо ошибкам в коде. Или они вообще возвращаются обратно в поисковик, потому что решение не найдено. Это всё сослужит плохую службу, ибо в итоге поведенческий фактор изменит позиции сайта в худшую сторону.
Как проверить сайт на валидность
Здесь перед Вами три варианта валидации:
Сервис указывает не только на ошибки html кода и их расположение, но и даёт советы по исправлению. Если код уже имеется в Сети, то можно произвести валидацию путём введения её URL-адреса в форму «Validate by URL» и нажатия кнопки Check. Валидатор HTML включит считывание кода и сообщит об итогах.
В этом видео наглядно объяснён процесс проверки с помощью валидатора:
Проверка локальных файлов
По этому же адресу http://validator.w3.org можно проверить код, выбрав вкладку «Validate by File Upload» и загрузив документ с прописанным код.
Выбираем путь к необходимому файлу и жмём Check. Далее всё происходит аналогично.
Использование формы для ввода кода
Иногда удобней вставить сразу код страницы и проверить его онлайн: выбираем вкладку «Validate by Direct Input» и отправляем весь код на сервер.
Проверка валидности кода CSS может быть пройдена также онлайн валидатором: https://jigsaw.w3.org/css-validator/
Здесь все на русском языке, для многих это действительно приятный сюрприз.
Снова можно выбрать — указать URL, загрузить свой файл или вставить код.
Осуществляется проверка сайта на ошибки, как и в случае с HTML, и — получаем ответ от сервера. Настроек проверки не имеется, однако можно изучить предлагаемый сгенерированный валидный код, расположенный после списка недостатков кода.
Изучаем полученный код и приводим исходный к нужному виду.
Расширения для браузеров
Для браузеров существуют всевозможные расширения для проверки валидации. Для Google Chrome есть проверяющий валидность кода плагин HTML Tidy Browser Extension, для Opera — расширение Validator, для Safari — Zappatic, для Firefor — HTML Validator.
Остановимся на последнем более детально. Он осуществляет ту же проверку, что и validator, только оффлайн. Взять его можно здесь http://users.skynet.be/mgueury/mozilla/
Подробное видео об установке HTML Validator и его использовании:
При загрузке любого URL расширение автоматически включается и считывает код. Результат виден в правом верхнем углу.
Выглядит результат как небольшая картинка с итогом валидации:
Щёлкнув по результату, можно открыть:
— исходный код;
— ошибки — в левом нижнем блоке (или сообщение о валидности);
— подсказки по исправлению ошибок — в правом нижнем.
Как исправить наиболее частые ошибки
Каким бы способом ни была проведена проверка кода, ошибки выходят списком. Также обязательно указана строка с недочётом.
В расширении для Firefox при нажатии на название ошибки в открытом окошке расширения вас автоматически перебрасывает на строку с невалидным кодом.
К этим же ошибкам указаны подсказки по их исправлению.
Приведу пару примеров.
1. No space between attributes.
…rel=»shortcut icon» href=»http://arbero.ru/favicon.ico» type=»image/x-icon»
Здесь исправления убираем «точку с запятой».
2. End tag for element «div» which is not open
Закрывающий тег div лишний. Убираем его.
Хотя, если честно, я бы не тратил много усилий на ошибки в коде. Лучше просто позаботьтесь о том, чтобы сайт корректно выглядел на всех устройствах и браузерах.
. Доклад Яндекса
«Просто добавь картинку на сайт», — говорили они. А оказалось, что «просто» не значит «правильно». В докладе я постарался разобраться, как эффективно добавлять изображения на страницу, какие форматы графики для каких случаев полезны и как автоматизировать автоматизируемое.
— Всем привет. У меня доклад с интригующим названием в виде одного тега.
Коротко представлюсь. Возможно, вы слышали о подкасте «Веб-стандарты» — иногда там можно услышать мой голос. И если новости в пабликах «Веб-стандартов» выходят с опечатками — скорее всего, это я. Работаю я в Яндекс.Поиске, разработчиком интерфейсов.
Сегодняшний доклад — по мотивам другого доклада. В 2019 году я успел вскочить в последний вагон и на последнем Web Standards Days прочитал доклад про ссылку.
Интригующее название было. Тогда из зала прозвучал вопрос: «Когда будет про следующие теги?» Сегодня вы смотрите доклад именно про следующий тег, о котором мне хотелось рассказать.
Начнем с истории. Шёл 1995 год. Тогда впервые появился тег img в стандарте HTML 2.0. Вы можете найти спецификацию — в то время они писались гораздо более сухо, чем сейчас. Но там есть интересные моменты.
В стандарте HTML 2.0 можно найти, что атрибутов у img тогда было не то чтобы много.
В 2020 году стандарт немножко поразноцветнее, и в нём гораздо больше подробностей.

Этого достаточно, чтобы начать работать с картинкой. JavaScript, например, может взять этот код и дополнить. Возможностей много.
Есть и другие сущности, которые можно получить из HTTP-заголовков. Их удобно использовать, чтобы экономить трафик, принимать другие решения.
Атрибут src — мощная и сложная штука, потому что это один из немногих способов внутри HTML дернуть какой-нибудь URL. Ссылка — первый способ, но ссылка — это когда ты кликаешь сам, осознанно. А здесь пользователь ничего не нажимает, но куда-то идет запрос. Здесь речь и про безопасность тоже. Та ещё задача.
Форматы графики могут быть разные: gif, jpeg, ico, png, apng, tiff, svg, webp, avif и так далее. Это самые популярные из них. TIFF, кстати, до сих поддерживается в Safari. Другие браузеры я не проверял. Но официально поддержки вроде как нет.
Мы уже доросли до того, что AVIF — это поддерживаемый браузерами формат графики.
Про форматы изображений я в 2018 году читал отдельный доклад.
Он был про то, как любым способом доставлять картинки (в том числе через background ), как и что сжимать.
Вот еще один способ дёрнуть какой-нибудь URL без HTML:
Нужно понимать, когда у картинки при загрузке вызывается обработчик onerror в коде выше. Это произойдет в нескольких случаях:
А вот такой пример мы же тоже в жизни видели, да?

Почему-то ресурсы не доходят, и браузер рисует какую-то странную иконку. Что нужно делать?

Есть важный нюанс: IMG — заменяемый элемент. Это значит, если картинка загрузилась, то всякие псевдоэлементы вы ему задать не можете — потому что IMG так себя ведет. Но если картинка не загрузилась, там появляется целый shadow-root, который вы можете посмотреть в Chrome DevTools, если поставите галочку «Show user agent shadow DOM» в настройках. Так можно увидеть, что вместо картинки показывается полноценный новый HTML. Вы можете добавлять туда псевдоэлементы before и after. И это можно использовать.
Например, Ире Адеринокун предлагает интересный способ.

Кажется, это даже можно автоматизировать. Например, парсить страницу через Puppeteer или еще чем-нибудь. Если какие-то картинки сломались, находите, какие именно, даже таким визуальным способом, и где-то их собираете. Хотя, конечно, профилировать запросы в сеть в этом смысле гораздо удобнее. Но есть и такой способ.
Но всё равно такой плейсхолдер выглядит не очень, да? А что, если мы его стилизуем?

Если у нас есть доступ к before и after, там же можно много чего натворить. Например, добавить after, приподнять его z-индексом над картинкой, чтобы не было видно стандартной иконки. И стилизуйте как хотите. Я эмодзи вставил — работает.
Главное — фантазия. У Лин Фишер, например, фантазии много, и есть сайт a.singlediv.com, где она на одном div делает целые анимированные произведения искусства. У вас есть before и after, целых два псевдоэлемента, которые можно стилизовать. Задумайтесь.
Но, допустим, мы вообще не хотим сломанных картинок. Можно ведь использовать сервис-воркер! Как с ними быть?
Еще один пример от Ире Адеринокун.
В сервис-воркере есть возможность, если мы вешаем обработчик на событие fetch и видим, что запрос сработал хорошо, просто вернуть его результат браузеру. Сходили за ресурсом — он есть — вернули.
Но есть два случая: либо мы сходили за ресурсом и ответ — не ок, либо на каком-то из этапов выбросилась ошибка. Это, скорее всего, значит, что пользователь в этот момент находится офлайн. Что можно сделать?
Можно определить, был ли это вообще поход за картинкой или не за картинкой, сделать вспомогательную функцию для этого.
Затем мы просто берем непонятные нам случаи — когда либо что-то с запросом, либо выбрасывается ошибка — и возвращаем из кэша уже то, что лежит на локальном устройстве пользователя.
Вместо непонятной дефолтной иконки мы можем вернуть стильный плейсхолдер. Не стесняйтесь призвать дизайнера в помощь, чтобы сделать это красиво, а не своими силами рисовать плейсхолдеры при помощи CSS.
Конечно, можно пойти дальше и вообще все картинки закэшировать, чтобы они всегда возвращались. Но это не так интересно.
Что будет, если мы атрибуту alt зададим пустое значение?
Во-первых, браузер не будет показывать эту сломанную иконку, когда картинка не загрузится. Вы даже не увидите, что у вас что-то не так. Не загрузилось, размеров нет, будет пусто. Во-вторых, для невизуальных браузеров это ещё и призыв не озвучивать картинку.
Таким образом, если у вас декоративное изображение, вы можете его спрятать.
Доступность
Картинки — визуальная штука. Людям с хорошим зрением, конечно, хорошо в интернетах сидеть и всё видеть, но я рекомендую вам сходить на weblind.ru, — отличный ресурс, где собраны рекомендации, как минимальными усилиями сделать ваши сайты чуть более доступными.
Короткая выдержка оттуда. Есть изображения информативные и декоративные. Информативные — это которые про контент, когда пишется текст, следом идёт картинка, которая дополняет этот текст, и вы в alt можете описать, что на этой картинке. Описывайте так, что если бы вы читали этот текст-описание, то как будто картинки даже не и было, можно её себе представить.
Декоративные — не несут особого смысла и, скорее всего, сделаны для красоты. Их можно спокойно выбросить, и ничего с текстом не случится.
У сайта «Веб-стандартов» есть CONTRIBUTING.md для тех, кто пишет статьи, переводы и так далее. У нас есть рекомендации, как всё это делать лучше. Совместно с Татьяной Фокиной сделали классные советы, которыми я хочу с вами поделиться.
Про пустой alt мы уже поговорили.
Это хорошие практики. Если действительно что-то мешает чтению картинки на слух, используйте их.
Если вы хотите запихнуть в картинку нечто сложное, например график, то я рекомендую посмотреть в сторону SVG и выставить для него правильную роль.
Здесь я рекомендую посмотреть замечательный доклад Сергея Кригера о том, как делать доступные графики, — на случай, если вам действительно нужно сделать график и описать его, чтобы все могли им пользоваться.
Вернёмся к котятам.
Размеры
Итак, вы указываете это значение ширины. Тогда возникает вопрос: откуда браузер берёт второй размер, высоту?
А если задать только высоту, как браузер рассчитывает ширину? Откуда он её берет?
Здесь можно копнуть глубже. Например, вы можете расковырять ваши картинки как бинарные файлы и посмотреть в спецификации.
В спецификации PNG первые восемь байт вообще прибиты гвоздями, эти байты и говорят, что это PNG-файл. Дальше всякая служебная информация, и есть кусочек, я его подсветил выше, который говорит: ширина и высота вот такие. Прямо в первых, буквально заголовочных кусках файла есть размеры.
С GIF всё ещё проще, потому что сам формат проще.
Тут можно сходу сказать, что у этой гифки размеры 500×275. Можно прямо в текстовом редакторе посмотреть.
С JPEG — сложнее. Cходу такой же красивый и наглядный пример вам собрать не смог, потому что там много интересного, но не очень очевидного. С WebP даже не пытался.
Но для любых графических форматов есть правило: в самом верху файла, буквально с первыми пакетами при скачивании приходит размер. Как только браузер делает запрос за картинкой, и картинка начинает приходить, браузер тут же выцепливает эти размеры и резервирует с их учётом под картинку место.
Очень рекомендую доклад Полины Гуртовой «Картинки как коробки. Что же там внутри?». Полина классно рассказала, как вообще всё внутри устроено, про разные форматы, в том числе про PNG, о котором я только что говорил. Есть видео и расшифровка на Хабре, обязательно почитайте.
Тут важно задавать правильные размеры. Я думаю, все вы видели эти ужасные случаи, когда прямоугольная картинка из-за криво заданных размеров зачем-то вписывается в квадрат, и получается нечто непропорциональное. Поэтому здесь хорошо бы, конечно, прикрутить какую-то автоматику. Но если вы делаете это руками, скорее всего в бизнес-процессах есть этап добавления картинки где-нибудь в вашей админке, если контентом занимается контент-менеджер. Там вы можете получить размеры, сохранить их в базу и потом подставлять эти размеры в клиентский код. Например, подставлять физические размеры картинки, как есть. А уже дальше в CSS вычислить, что с ними делать.
Но на самом деле нет, уже не можем. Авторы спецификаций обсуждали-обсуждали и пришли к тому, что, кажется, можно сделать более элегантно.
Поддержка у этого свойства достаточно хорошая, на мое удивление. Уже можно, даже нужно, 66% пользователей будут счастливы.

Загрузка
Дальше можно поиграться с тем, как вообще эту картинку получить.
Для начала можем задать, какую информацию мы отправляем на сервер. Вы же иногда подключаете картинки из каких-нибудь CDN или с внешних ресурсов, не только у себя их держите.
В данном случае я чётко говорю браузеру: отправляй, пожалуйста, только домен и все. Больше ничего не надо, полный URL отправлять не надо. В конце концов это тоже информация, которую тот, кто хранит картинку, может использовать.
Ещё один вариант — это когда вы ходите за картинкой на другой домен.
Понятно, что мы, разработчики, можем эту картинку скачать себе любым другим способом и расковырять её у себя локально. Но если вы не настроили cross-origin запрос, то от браузера получите ошибку DOMException. Она будет говорить: простите, данные с другого домена — нельзя. И в этом случае нужно добавить атрибут crossorigin картинке, чтобы всё заработало.
У него есть в том числе и значение. По умолчанию это анонимный CORS-запрос. Он такой идёт на сервер: «Ну, пожалуйста, можно я поковыряюсь в байтиках?» И если сервер в ответ: «А, давай! Пожалуйста, на тебе Accept, бери всё и ковыряй», — то в canvas вы сможете поиграться с данными.
На самом деле это история не только про canvas. Например, вы хотите бинарные данные в LocalStorage положить. Подходов и применений много, но вам нужно получить доступ к бинарникам.
Яркий пример — CodePen. Если вы там когда-нибудь рисовали на canvas что-то из внешних изображений, то, возможно, сталкивались с ошибкой доступа к данным. Я сталкивался. Приходилось хранить картинки в base64, потому что у меня бесплатный аккаунт.
И он вроде как классный, но есть нюансы. У него три значения:
Но, например, в исходном коде Chromium можно найти такие интересные настройки.
Offline — 8000
Slow 2G — 8000
2G — 6000
3G — 2500
4G — 1250
Когда соединение офлайн или очень медленное, то браузер загружает все картинки в пределах 8000 пикселей от текущего вьюпорта. При этом на самом быстром соединении — в пределах 1250 пикселей.
Причем значения постоянно меняются. Я так понимаю, разработчики браузеров проводят замеры, эксперименты, в интернете идут холивары, какие числа более правильные, потому что каждый браузер немножко по-своему их подбирает.
Чем хуже соединение, тем больше картинок качается. Это не очень очевидно, и вам нужно понимать, что это не про экономию трафика, а именно про скорость соединения.
Зачем так сделано — объяснение простое. Пользователь обычно страницы скроллит. И на медленном соединении, пока он доскроллит, уже всё должно быть хорошо, хорошо видны картинки. У пользователя должен быть потрясающий опыт пользования вашей страницей.
Чем медленнее соединение, тем раньше за картинкой нужно сходить. На быстром соединении оно вроде как быстро загрузится, зачем париться?
Но эти значения — 1250 — достаточно большие. Используйте на свой страх и риск, если вы в первую очередь задумывались про экономию трафика, а не про скорость.
В официальной статье про lazy loading на web.dev описан способ, как это сделать с поддержкой браузеров, которые не умеют в нативную ленивую загрузку.
Если нет, то взять библиотечку, которая сделает то же самое, но уже без браузерных механизмов. Если вновь поковыряться в коде того же Chromium, там точно так же создается Intersection Observer, как если бы вы это делали руками. И точно так же, но с более внутренними механизмами, делается всякая магия: «Ага, здесь мы определяем, сколько до вьюпорта, дальше качаем».
Это когда вы уже прямо тюните сайт под перформанс.
В голове у нас процесс такой: картинка загрузилась, потом нарисовалась. На самом деле в серединке, между «загрузилось» и «нарисовалось», есть декодинг и ресайз картинки, не нулевые по времени процессы.
Декодинг картинки на среднестатистическом устройстве Moto G — это 300 миллисекунд в примере Эдди, заметно даже глазом. Стоит задуматься, что большие картинки декодируются дольше и, может, их надо позже декодировать, если не хотим зря тратить ресурсы. Важно: желательно не давать браузеру и ресайзить тоже. Пускай сразу приходит только самое нужное.
Помните: когда у вас выполняется JS, он блокирует основной поток. Будем считать, что браузер однопоточный, и вы блокируете рендеринг. Если вы выполняете долгий JS, то и картинка не нарисуется. Потому что браузер в этот момент занят, он ваш while (true) обрабатывает.
Здесь самое интересное. Спеки четко не прописаны, инструкция — грузить изображение, которое явно больше. То есть браузеры решают сами, как это оптимально сделать. И в разных браузерах поведение разное.
В srcset ещё можно указывать плотность пикселей.
Иначе вы будете очень долго дебажить, почему вы просите одну картинку загрузить, а она вообще не та.
Вы можете позамерять, насколько эффективно вы используете картинки на странице. Например, я зашел на сайт GDG Russia при помощи пакета imaging-heap от Filament Group.
Прелесть в том, что мы можем поддерживать разные форматы. Не так уж давно зарелизился формат AVIF, в Chrome он уже поддерживается.
У Джейка Арчибальда есть потрясающая статья, которая объясняет, почему этот формат клёвый, в каких случаях он работает хорошо. Вы можете увидеть, что для некоторых картинок AVIF сжимает лучше, чем SVG. У меня в голове это по первости не укладывалось — это же векторный формат, а нас учили, что векторный формат занимает мало. Ничего подобного.

AVIF — это видеокодек AV1, который оптимизирован и адаптирован под изображения. Внезапно видеокодек позволяет сжимать картинки лучше, чем специальные картиночные форматы.
Обязательно посмотрите в статье Джейка, что это за формат такой. Кажется, его уже пора использовать.
Ингвар Степанян в твиттере поделился отличным способом, как вообще при помощи JavaScript минимальным кодом определять, поддерживает ли браузер тот или иной формат.
Ещё у нас есть медиавыражения. Мы можем точно так же под разные медиавыражения получать разные картинки. Например, смотрим на высоту изображения, ширину вьюпорта и берем более широкую, десктопную картинку. А для маленьких экранов — мобильную.
Звучит страшно: WebP, AVIF, JPG, PNG, все эти retina, да еще и под разные размеры! Как с этим работать?
Можно, конечно, попробовать руками.
Я обожаю инструмент Squoosh, там уже поддерживается AVIF. Так вот, Squoosh позволяет сжимать картинки, менять их размеры и не только. Но руками это долго.
Ещё пользуюсь ImageOptim. Например, некоторые картинки для этого доклада сжаты там. Тоже потрясающий инструмент. Но это всё — не автоматизация.
Для доклада собрал свой подход. Я фанат Gulp. Можете посмотреть у меня в репозитории: mefody/image-processor.
Использую простые пакеты: gulp-imagemin, gulp-responsive, imagemin-guetzli, imagemin-pngquant, imagemin-svgo, imagemin-webp. Думаю, у вас может быть похоже.
Я просто из этого стартера собираю себе почти под любой проект оптимизатор картинок, который распиливает их по разным размерам. gulp-imagemin внутри себя содержит imagemin.
Чем этот пакет хорош? Тем, что туда можно подключать новые плагины. Но там пока нет поддержки AVIF (на момент подготовки доклада — прим. автора).
Зато там есть поддержка Guetzli. Этот алгоритм тоже разработан в Google. В чем его суть?
Что обычно делают оптимизаторы? Они снижают качество у JPG, не меняя информацию о цвете. А Guetzli ещё и меняет цвета картинок, но так, чтобы визуально для глаза это почти не чувствовалось. Ключевое слово — «почти». И оказывается, за счёт такого незаметного изменения цветов можно сделать сжатие значительно круче.
Но происходит страшное. Даже на картинке 1000×1000 у вас начинает жужжать ноутбук, всё это обрабатывается очень долго. Алгоритм банально делает очень много разных переборов и сравнений. При этом сжимает настолько потрясающе, что у меня JPG обычно весят меньше, чем WebP. Поэтому я могу из своих source в принципе выкидывать ненужный мне WebP. Но, кстати, объём у сжатых через Guetzli картинок всё равно больше, чем у AVIF. Я попробовал.
Кстати, «guetzli» — это, я так понимаю, сладость, скандинавская выпечка. Как-то в подкасте мы пытались выяснить, что такое guetzli, brotli, zopfli. Оказалось, всё это — выпечка.
AVIF уже, на самом деле, в gulp засунуть можно, но через костыли.
Для этого ещё нужно дополнительное шевеление бубном на Mac.
Я устанавливаю пакеты через brew. avifenc — это C++-пакет, который умеет работать с AVIF.
Словом, работу с AVIF уже можно автоматизировать. Не ленитесь.
Что ещё можно делать? Например, дёргать всего одну картинку, которую положить на CDN, который будет сам решать, что отдавать.
Например, у «Злых Марсиан» есть проект imgproxy. Очень рекомендую вам на него посмотреть. С ним можно всевозможными настройками задать размер, retina/не retina. Даже водяные знаки можно рисовать. Подобные CDN позволяют вам не думать про сборку. У вас есть только исходник, а уже CDN берет на себя часть работы, чтобы этот исходник, например, при первом обращении обработать, закэшировать и отдать.
Ещё одна важная штука. В media вы можете задавать любые медиазапросы, не только про ширину и высоту. Например, можно подсмотреть, что у пользователя установлена настройка, что он любит тёмную тему.
Раз он выставил её у себя в системе, так дайте ему отдельную картинку для тёмной темы. Потому что если вы на черной странице нарисуете яркую белую гифку, пользователь чуть-чуть ослепнет и будет ваш сайт чуть-чуть не любить.
Когда пользователь будет между разными темами переключаться, это, кстати, может произвести вау-эффект.
Ещё важно помнить про пользователей, которые не любят движение на сайтах.
А вот если пользователь нормально относится к гифкам, рисуйте ему эти гифки. Хотя есть отдельный доклад Вадима Макеева pepelsbey «Делайте из слона муху», где он говорит, что не надо. Лучше подключайте видео, потому что GIF безумно много весит.
Пятиминутка ностальгии
И другие атрибуты, из прошлого.
Это прикольно, и, кстати, оно до сих пор работает в браузерах. Кажется, в Safari есть нюансы, но в целом вроде как работает. Сейчас непонятно, зачем, но поиграться можно.
Таким образом можно одну картинку-меню сделать, обработать на сервере, узнать, куда пользователь кликнул. И, например, нарисовать иконки, в которые надо кликать.
Так делали раньше. Сейчас я таких обработчиков уже не встречал, но если хотите поприкалываться, почему бы и нет.
И есть deprecated-атрибуты, такие как align, border, hspace, vspace, name, onerror. Они браузерами всё ещё поддерживаются. Работает обратная совместимость веба: нельзя просто сломать половину сайтов.
Но считается, что вместо них уже нужен CSS. Причем атрибут align работает интересно, позволяет внутри блоков всякое выравнивать. Вроде как можно через float это всё сделать, но align более гибкий, что ли. Мне он в своё время нравился, а сейчас он уже deprecated.
Рамки
Есть задача, которая часто встаёт перед разработчиками, — поместить картинку в какие-то рамки.
Если просто выровнять по ширине — пожалуйста.
Максимальную ширину ставим 100%, высоту — auto, и браузер масштабирует как надо. Всё будет хорошо для горизонтальных картинок.
А что если нам нужны заданные пропорции? Например, часто есть такой заказ: «Давай вставим превьюшку с YouTube, которая обязательно должна быть 16×9».
Есть старый-добрый padding-хак.
Поддержка уже хорошая, но если вам нужно поддерживать много всякого, то, опять же, у Вадима Макеева на его канале есть подробный разбор.
Кадрирование
Which will the Twitter algorithm pick: Mitch McConnell or Barack Obama? pic.twitter.com/bR1GRyCkia
Но будьте аккуратны, потому что Twitter с таким угодил в скандал. Оказалось, что алгоритм, который определял, как правильней кадрировать, был расистским. Публично извинялись. Машинное обучение — вроде крутая штука, но там ещё очень много проблем в том, как определить, что показывать.
Мне нравится подход, который случайно нашел на CodePen.
Вы можете использовать две картинки, тогда у вас не будет пустого пространства. Точнее, URL у картинок одинаковый. Но подключаете вы их в контейнере друг за дружкой. Первую прячете, чтобы ее не было слышно, например, на скринридере.
В итоге у вас получается вот такой эффект:
Красиво. На YouTube некоторые блогеры вертикальные видео похоже обрабатывают.
По ссылочке есть полный код, как это сделать. Мне такой подход больше нравится, потому что мы хотели заполнить всё, — заполнили, при этом картинку видно всю, а мы ничего лишнего не обрезали.
Знаете, что у картинок есть в CSS особенность — там можно задавать способ, как их рендерить?

По умолчанию браузер, увеличивая вашу картинку, как-то её смазывает. Есть алгоритм, который делает это сглаживание. Вы можете сказать: «Нет, браузер, я хочу pixelated». И, увеличивая картинку, он будет реально рисовать чёткие границы пикселей.
Это полезно, если у вас, например, сайт про пиксельную графику, Lego, что-то с этим связанное. Я на некоторых сайтах видел — обалденный эффект. Выставляете маленькую иконку, скажем, 12×12, растягиваете ее, и такой пиксельный эффект сохраняется. Это ещё и обалденная экономия трафика.
Быстрее
Как можно еще быстрее грузить картинки?
Есть подробный разбор от Эдди Османи, как эта штука работает. Можете посмотреть, как preload помогает ресурсы больше скомпоновать и загрузиться быстрее.
Итоги
Надеюсь, image-processor, который я для вас собрал, будет вам полезен. Я, по крайней мере, им пользуюсь. Может, и вам пригодится.
Есть еще классные материалы, которые я могу посоветовать:


