Сравнение OpenCL с CUDA, GLSL и OpenMP

На хабре уже рассказали о том, что такое OpenCL и для чего он нужен, но этот стандарт сравнительно новый, поэтому интересно как соотносится производительность программ на нём с другими решениями.
В этом топике приведено сравнение OpenCL с CUDA и шейдерами для GPU, а также с OpenMP для CPU.
Тестирование проводилось на задаче N-тел. Она хорошо ложится на параллельную архитектуру, сложность задачи растёт как O(N 2 ), где N — число тел.
Задача
В качестве тестовой была выбрана задача симуляции эволюции системы частиц.
На скриншотах (они кликабельны) видна задача N точечных зарядов в статическом магнитном поле. По вычислительной сложности она ничем не отличается от классической задачи N тел (разве что картинки не такие красивые).
Во время проведения замеров вывод на экран был отключен, а FPS означает число итераций в секунду (каждая итерация — это следующий шаг в эволюции системы).
Результаты
Код на GLSL и CUDA для этой задачи был уже написан сотрудниками ННГУ.
NVidia Quadro FX5600
Версия драйвера 197.45 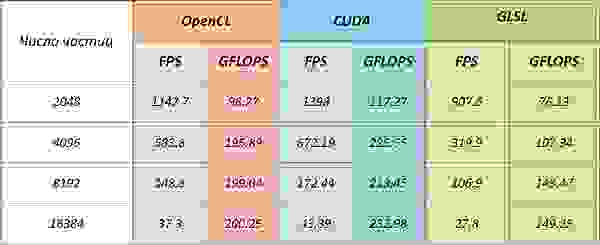
CUDA обгоняет OpenCL приблизительно на 13%. При этом, если оценивать теоретически возможную производительность для этой задачи для данной архитектуры, реализация на CUDA достигает её.
(В работе A Performance Comparison of CUDA and OpenCL говорится о том, что производительность ядра OpenCL проигрывает CUDA от 13% до 63% )
Несмотря на то, что тесты проводились на карточке серии Quadro, понятно, что обычный GeForce 8800 GTS или GeForce 250 GTS дадут схожие результаты (все три карточки основаны на чипе G92).
Radeon HD4890
ATI Stream SDK версия 2.01 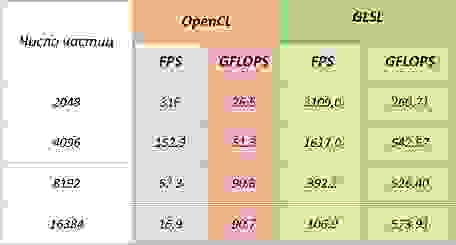
OpenCL проигрывает шейдерам на карточках от AMD так как вычислительный блоки на них имеют архитектуру VLIW, на которую (после оптимизации) могут хорошо лечь многие шейдерные программы, но компилятор для кода OpenCL (который является частью драйвера) плохо справляется с оптимизацией.
Также этот весьма скромный результат может быть вызван тем, что карточки от AMD не поддерживают локальную память на физическом уровне, а отображают область локальной памяти на глобальную.
Код с использованием OpenMP был скомпилирован при помощи компиляторов от Intel и Microsoft.
Компания Intel не выпустила своих драйверов для запуска кода OpenCL на центральном процессоре, поэтому был использован ATI Stream SDK.
Intel Core2Duo E8200
ATI Stream SDK версия 2.01 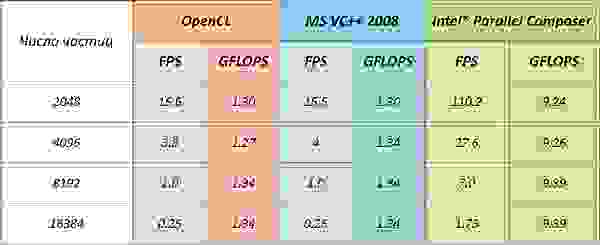
Код на OpenMP, скомпилированный при помощи MS VC++ имеет практически идентичную производительность с OpenCL.
Это ещё при том, что Intel не выпустил своего драйвера для интерпретации OpenCL, и используется драйвер от AMD.
Компилятор от Intel поступил не совсем «честно» он полностью развернул основной цикл программы, повторив его где-то 8k раз (число частиц было задано константой в коде) и получив семикратный прирост производительности также благодаря использованию SSE инструкций. Но победителей, конечно, не судят.
Что характерно, на моём стареньком AMD Athlon 3800+ код тоже запустился, но таких выдающихся результатов, как на Intel, конечно, ждать не приходится.
Заключение
OpenCL. Что это такое и зачем он нужен? (если есть CUDA)

Здравствуй, уважаемое хабра-сообщество.
Многие, наверное, слышали или читали на хабре об OpenCL – новом стандарте для разработки приложений для гетерогенных систем. Именно так, это не стандарт для разработки приложений для GPU, как многие считают, OpenCL изначально задумывался как нечто большее: единый стандарт для написания приложений, которые должны исполняться в системе, где установлены различные по архитектуре процессоры, ускорители и платы расширения.
Предпосылки появления OpenCL
Стоит отметить, что подобные программы создавались и раньше, но именно NVidiaа CUDA обеспечила рост популярности GPGPU за счет облегчения процесса создания GPGPU приложений. Первые GPGPU приложения в качестве ядер (kernel в CUDA и OpenCL) использовали шейдеры, а данные запаковывались в текстуры. Таким образом необходимо было быть хорошо знакомым OpenGL или DirectX. Чуть позже появился язык Brook, который немного упрощал жизнь программиста (на основе этого языка создавалась AMD Stream (в ней используется Brook+) ).
CUDA стала набирать обороты, а между тем (а точнее несколько ранее) в кузнице, расположенной глубоко под землей, у подножия горы Фуджи (Fuji), японскими инженерами был выкован процессор всевластия Cell (родился он в сотрудничестве IBM, Sony и Toshiba). В настоящее время Cell используется во всех суперкомпьютерах, поставляемых IBM, на его основе постоены самые производительные в мире суперкомпьютеры (по данным top500). Чуть менее года назад компания Toshiba объявила о выпуске платы расширения SpursEngine для PC для ускорения декодирования видео и прочих ресурсоемких операций, используя вычислительные блоки (SPE), разработанные для Cell. В википедии есть статья, в кратце описывающая SpursEngine и его отличия от Cell.
Примерно в то же время (около года назад) оживилась и S3 Graphics (на самом деле VIA), представив на суд общественности свой новый графический адаптер S3 Graphics Chrome 500. По заявлениям самой компании этот адаптер так же умеет ускорять всяческие вычисления. В комплекте с ним поставляется программный продукт (графический редактор), который использует все прелести такого ускорения. Описание технологии на сайте производителя.
Итак, что мы имеем: машина, на которой проводятся вычисления может содержать процессоры x86, x86-64, Itanium, SpursEngine (Cell), NVidia GPU, AMD GPU, VIA (S3 Graphics) GPU. Для каждого из этих типов процессов существует свой SDK (ну кроме разве что VIA), свой язык программирования и программная модель. То есть если Вы захотите чтобы ваш движок рендеринга или программа расчета нагрузок на крыло боинга 787 работала на простой рабочей станции, суперкомпьютере BlueGene, или компьютере оборудованном двумя ускорителями NVidia Tesla – Вам будет необходимо переписывать достаточно большую часть программы, так как каждая из платформ в силу своей архитектуры имеет набор жестких ограничений.
Так как программисты – народ ленивый, и не хотят писать одно и то же для 5 различных платформ с учетом всех особенностей и учиться использовать разные программные средства и модели, а заказчики – народ жадный и не хотят платить за программу для каждой платформы как за отдельный продукт и оплачивать курсы обучения для программистов, было решено создать некий единый стандарт для программ, исполняющихся в гетерогенной среде. Это означает, что программа, вообще говоря, должна быть способна исполняться на компьютере, в котором установлены одновременно GPU NVidia и AMD, Toshiba SpursEngine итд.
Решение проблемы
Для разработки открытого стандарта решили привлечь людей, у которых уже есть опыт (весьма успешный) в разработке подобного стандарта: Khronos Group, на чьей совести уже OpenGL и OpenML и еще много всего. OpenCL является торговой маркой Apple Inc., как сказано на сайте Khronos Group: «OpenCL is a trademark of Apple Inc., and is used under license by Khronos. The OpenCL logo and guidelines for its usage in association with Conformant products can be found here:
http://developer.apple.com/softwarelicensing/agreements/opencl.html». В разработке (и финансировании, конечно же), кроме Apple, участвовали такие воротилы IT как AMD, IBM, Activision Blizzard, Intel, NVidia итд. (полный список тут).
Компания NVidia особо не афишировала свое участие в проекте, и быстрыми темпами наращивала функциональность и производительность CUDA. Тем временем несколько ведущих инженеров NVidia участвовали в создании OpenCL. Вероятно, именно участие NVidia в большой мере определило синтаксическую и идеологическую схожесть OpenCL и CUDA. Впрочем программисты от этого только выиграли – проще будет перейти от CUDA к OpenCL при необходимости.
Первая версия стандарта была опубликована в конце 2008 года и с тех пор уже успела претерпеть несколько ревизий.
Почти сразу после того как стандарт был опубликован, компания NVidia заявила что поддержка OpenCL не составит никакой сложности для нее и в скором времени будет реализована в рамках GPU Computing SDK поверх CUDA Driver API. Ничего подобного от главного конкурента NVidia – AMD слышно не было.
Драйвер для OpenCL был выпущен NVidia и прошел проверку на совместимость со стандартом, но все еще доступен только для ограниченного круга людей – зарегистрированных разработчиков (заявку на регистрацию подать может любой желающий, в моем случае рассмотрение заняло 2 недели, после чего по почте пришло приглашение). Ограничения доступа к SDK и драйверам заставляют задуматься о том, что на данный момент существуют какие-то проблемы или ошибки, которые пока не удается исправить, то есть продукт все еще находится в стадии бета-тестирования.
Реализация OpenCL для NVidia была достаточно легкой задачей, так как основные идеи сходны: и CUDA и OpenCL – некоторые расширения языка С, со сходным синтаксисом, использующие одинаковую программную модель в качестве основной: Data Parallel (SIMD), так же OpenCL поддерживает Task Parallel programming model – модель, когда одновременно могут выполняться различные kernel (work-group содержит один элемент). О схожести двух технологий говорит даже то что NVidia выпустила специальный документ о том как писать для CUDA так, чтобы потом легко перейти на OpenCL.
Как обстоят дела на настоящий момент
Основной проблемой реализации OpenCL от NVidia является низкая производительность по сравнению с CUDA, но с каждым новым релизом драйверов производительность OpenCL под управлением CUDA все ближе подбирается к производительности CUDA приложений. По заявлениям разработчиков такой же путь проделала и производительность самих CUDA приложений – от сравнительно невысокой на ранний версиях драйверов до впечатляющей в настоящее время.
А что же делала в этот момент AMD? Ведь именно AMD (как сторонник открытых стандартов – закрытый PhysX vs. открытый Havoc; дорогой Intel Thread Profiler vs. бесплатный AMD CodeAnalyst) делала большие ставки на новую технологию, учитывая что AMD Stream не удавалось хоть сколь-нибудь соревноваться в популярности с NVidia CUDA – виною тому отставание Stream от CUDA в техническом плане.
Летом 2009 года компания AMD сделала заявление о поддержке и соответствии стандарту OpenCL в новой версии Stream SDK. На деле же оказалось, что поддержка была реализована только для CPU. Да, именно так, это ничему не противоречит – OpenCL стандарт для гетерогенных систем и ничего не мешает Вам запустить kernel на CPU, более того – это очень удобно в случае если в системе нет другого OpenCL устройства. В таком случае программа будет продолжать работать, только медленнее. Или же вы можете задействовать все вычислительные мощности, которые есть в компьютере – как GPU так и CPU, хотя на практике это не имеет особого смысла, так как время исполнения kernel’ов которые исполняются на CPU будет намного больше тех что исполняются на GPU – скорость процессора станет узким местом. Зато для отладки приложений это более чем удобно.
Поддержка OpenCL для графических адаптеров AMD так же не заставила себя долго ждать – по последним сообщениям компании версия для графических чипов сейчас находится на стадии подтверждения соответствия спецификациям стандарта. После чего она станет доступна всем желающим.
Так как OpenCL должен работать поверх некоторой специфической для железа оболочки, а значит для того чтобы можно этот стандарт действительно стал единым для различных гетерогенных систем – надо чтобы соответствующие оболочки (драйверы) были выпущены и для IBM Cell и для Intel Larrabie. Пока от этих гигантов IT ничего не слышно, таким образом OpenCL остается еще одним средством разработки для GPU на ряду с CUDA, Stream и DirectX Compute.
Заключение
Технология OpenCL представляет интерес для различных компания IT сферы – от разработчиков игр до производителей чипов, а это означает что у нее большие шансы стать фактическим стандартом для разработки высокопроизводительных вычислений, отобрав этот титул у главенствующей в этом секторе CUDA.
В будущем я планирую более подробную статью о самом OpenCL, описывающую что из себя представляет эта технология, ее особенности, достоинства и недостатки.
Спасибо за внимание.
Что лучше Cuda или OpenCL?
По общему мнению, если ваше приложение поддерживает как CUDA, так и OpenCL, переходите на CUDA, так как это даст лучшие результаты производительности. … Если вы включаете OpenCL, можно использовать только 1 графический процессор, однако, когда включен CUDA, для GPGPU можно использовать 2 графических процессора.
Что быстрее Cuda или OpenCL?
Если у вас есть карта Nvidia, используйте CUDA. В большинстве случаев он считается быстрее, чем OpenCL. Также обратите внимание, что карты Nvidia поддерживают OpenCL. По общему мнению, они не так хороши в этом, как карты AMD, но они все время приближаются.
В чем разница между OpenCL и Cuda?
CUDA и OpenCL предлагают два разных интерфейса для программирования графических процессоров. OpenCL — это открытый стандарт, который можно использовать для программирования процессоров, графических процессоров и других устройств от разных поставщиков, в то время как CUDA специфичен для графических процессоров NVIDIA.
Стоит ли изучать Cuda?
Если вы «редактируете видео» в Premiere Pro, то да, CUDA того стоит. Это не панацея, но значительно ускоряет выполнение некоторых задач. dmeyer: Если вы «редактируете видео» в Premiere Pro, то да, CUDA того стоит.
OpenCL мертв?
Фактически OpenCL вымер в пользу CUDA, а затем некоторые члены Khronos сформировали HSA Foundation, но он тоже вымер, так что теперь мы находимся в этом месте, где у нас есть AMD ROCm / HIP и Intel oneAPI / DPC ++ (SYCL со специальными расширениями Intel).
Что означает Cuda?
CUDA (аббревиатура от Compute Unified Device Architecture) — это платформа параллельных вычислений и модель интерфейса прикладного программирования (API), созданная Nvidia.
Nuke 12.0 имеет новые инструменты с ускорением на графическом процессоре, интегрированные из Cara VR для решения проблем с камерой, сшивания и исправлений, с обновлениями в соответствии с самыми последними стандартами.
Чем хорош Cuda?
CUDA — это платформа параллельных вычислений и модель программирования, разработанная Nvidia для общих вычислений на собственных графических процессорах (графических процессорах). CUDA позволяет разработчикам ускорить приложения с интенсивными вычислениями за счет использования мощности графических процессоров для параллелизируемой части вычислений.
OptiX быстрее, чем Cuda?
Если у вас есть графический процессор Nvidia, вы можете использовать CUDA или OptiX. OptiX специально создан для трассировки лучей и, вероятно, быстрее, чем CUDA, созданный для общих вычислений.
Есть ли у AMD эквивалент Cuda?
CUDA — это просто проприетарная версия OpenCL. В настоящее время королем является Vulkan, который был изобретен AMD как AMD Mantle API.
Сложно ли программировать на Cuda?
Вердикт: CUDA — это сложно. Вкратце, CUDA — это набор инструментов, библиотек и расширений языка C, которые позволяют разработчикам иметь более легко обобщаемый и низкоуровневый доступ к оборудованию G8800, чем это предоставляют типичные графические библиотеки.
Поддерживают ли карты Nvidia OpenCL?
Графические процессоры NVidia
NVidia хорошо поддерживает OpenCL на устройствах с Compute Capability 1.3 и выше, а именно: GeForce GTX 260 и выше. GeForce GTX 400 серии.
OpenCL работает с Nvidia?
Используя OpenCL API, разработчики могут запускать вычислительные ядра, написанные с использованием ограниченного подмножества языка программирования C на графическом процессоре. Помимо OpenCL, NVIDIA поддерживает множество библиотек с ускорением на GPU и программных решений высокого уровня, которые позволяют разработчикам быстро приступить к вычислениям на GPU.
Поддерживает ли AMD OpenCL?
ROCm (Radeon Open Compute), созданный как часть AMD GPUOpen, представляет собой проект Linux с открытым исходным кодом, построенный на OpenCL 1.2 с языковой поддержкой 2.0. Система совместима со всеми современными процессорами и APU AMD (фактически частично GFX 7, GFX 8 и 9), а также с процессорами Intel Gen7.5 + (только с PCI 3.0).
OpenCL устарел?
Спустя более десяти лет с момента создания экосистема вычислений на графических процессорах разрушается: интерес NVIDIA сдерживается тем фактом, что у них уже есть свой очень успешный API CUDA, драйверы AMD OpenCL — беспорядок, Apple устарела и переходит на собственный проприетарный Metal API.
Что такое OpenCL против OpenGL?
Основное различие между OpenGL и OpenCL заключается в том, что OpenGL используется для программирования графики, а OpenCL используется для гетерогенных вычислений. … OpenGL позволяет писать программы для выполнения графических операций, в то время как OpenCL позволяет писать программы для гетерогенных систем, состоящих из нескольких процессоров.
OpenCL в Adobe Premiere Pro: насколько GPU быстрее CPU?
Привет, Гиктаймс! Открыв недавно для себя прекрасный мир ускорения обработки данных силами видеокарт с помощью OpenCL, я решил написать небольшой вводный материал для новичков, не знакомых с этой технологией на практике. В Интернете нередко встречаются вопросы «какой прирост производительности я получу?», но ответы бывают либо абстрактными, либо излишне теоретизированными.
Этот пост призван наглядно показать, как применение OpenCL способно ускорить рендеринг видео в программах видеомонтажа. Глубокого погружения в теорию и матан вы не встретите – подробных теоретических статей про OpenCL на Гиктаймсе и Хабре предостаточно и без меня. Здесь будет только описание задачи и результаты тестов, поэтому прошу относиться к тексту именно как к простому вводному гайду для начинающих.
Зачем оно нужно?
Современные видеокарты – это настоящие вычислительные монстры, вся мощь которых обычно тратится на игры. Неглупые люди смекнули, что если организовать программистам прямой доступ к вычислительным блокам видеочипов, то можно всю эту колоссальную мощь задействовать под любые другие задачи, а не только обработку 3D-графики.
Первой в реализации этой идеи преуспела компания NVIDIA со своей архитектурой параллельных вычислений CUDA (Compute Unified Device Architecture). При помощи расширенного синтаксиса языка C и особого компилятора разработчики получили возможность задействовать для вычислительных задач графический чип. AMD, в свою очередь, представила Stream SDK – свое фирменное видение CUDA.
Результат был феноменальный – процессы, связанные с обработкой медиаданных, что подразумевает высокий уровень распараллеливания, завершались в разы быстрее, чем в случае вычислений силами центрального процессора. Особенно явно преимущество GPU проявлялось при рендеринге в программах 3D-моделирования и видеообработке.
Год спустя после выхода CUDA консорциум Khronos Group выпустил фреймворк OpenCL. Фактически он должен был унифицировать код для доступа к вычислительным мощностям процессоров на разных архитектурах, включая видеоядра. С этого момента в профессиональный софт начала активно внедряться поддержка нового фреймворка.
На сегодняшний день OpenCL поддерживают программы Adobe, медиаконвертеры, ряд популярных 3D-рендеров, CAD и софт для математического моделирования.
Лучше CUDA или OpenCL?
Очень частый и очень интересный вопрос вынесен в подзаголовок. Эти две технологии, как непохожие братья. Как и многострадальный PhysX, CUDA – технология закрытая, поддерживаемая только чипами NVIDIA и далеко не всем специализированным ПО. OpenCL – экстраверт, код открыт любому энтузиасту, любое ПО с поддержкой вычислений на GPU по определению работает с OpenCL.
Программисты NVIDIA не лаптем щи хлебают – если взять две сферические видеокарты в вакууме с одинаковой производительностью, то CUDA на чипе NVIDIA показывает в среднем на 20% большую производительность, чем OpenCL на чипе AMD. Но есть, как говорится, нюанс – если CUDA от NVIDIA работает быстро и хорошо, то OpenCL на картах этой компании немного уступает скорости обработки OpenCL от AMD. Несколько лет назад ситуация была совсем плачевная, но со временем с помощью драйверов разрыв удалось наверстать. Тем не менее, удельная производительность NVIDIA GeForce в OpenCL до сих пор немного ниже таковой у AMD Radeon. Поэтому в самом дурном положении окажутся те, кто приобрёл карту NVIDIA для работы с приложением, поддерживающим исключительно OpenCL — сам адаптер выйдет дороже, а его эффективность может быть ниже, чем у Radeon. Такая игра свеч не стоит.

Железо
Прекрасный мир OpenCL я открыл для себя лишь этим летом, купив сразу две видеокарты AMD Radeon серии 300: SAPPHIRE NITRO R9 380 и SAPPHIRE Tri-X R9 390X. Одну из них планировалось сдать обратно в магазин в зависимости от результатов домашних тестов. Карты покупались для надомного видеомонтажа, выбор в сторону Radeon был вполне осознанным: с одной стороны, CUDA работает быстрее, чем OpenCL. С другой, как выяснилось, OpenCL поддерживается значительно большим количеством профессионального софта, чем CUDA, а производительность карт NVIDIA в OpenCL оставляет желать лучшего.

Из предложенного ассортимента карты SAPPHIRE мне понравились более остальных. В отличие от любителей референсного дизайна, SAPPHIRE использует в системе охлаждения классические вентиляторы, которые работают значительно тише референсных центробежных ветродуев – к таким у меня выработалась стойкая неприязнь после беглого знакомства с видеокартой-пылесосом Radeon 4870×2.
Дома при распаковке двух огромных коробок я почувствовал себя замшелым мастодонтом – видеокарты немаленькие. SAPPHIRE R9 390X так и вовсе огромная, с тремя вентиляторами и радиатором, превышающим размеры печатной платы. Сперва я даже поволновался, влезут ли эти монстры в мой корпус. К счастью, влезли, но из корзины для жестких дисков пришлось демонтировать один хард. Киловаттный блок питания также был не лишним – R9 390X требует два четырехконтактных разъема питания, а такой ток вытянет не каждый БП.

Если Adobe Premiere Pro CS4 был тяжким грузом в офисе, то дома можно было организовать рабочее пространство по своему вкусу. Едва ли я когда-нибудь задумался бы о покупке Premiere Pro, если бы Adobe не выкатила замечательную, на мой взгляд, систему подписки Creative Cloud. Теперь за 600 рублей в месяц я имею легальный и постоянно обновляемый Premiere Pro CC. И он-то, в отличие от офисного старикана, нативно поддерживает рендеринг с помощью OpenCL и CUDA!
Если ваша видеокарта работает с OpenCL или CUDA, то еще на стадии создания проекта в Premiere Pro можно выбрать рендер. За аппаратное ускорение отвечает Mercury Playback Engine GPU (OpenCL) или (CUDA). В уже готовом проекте рендер можно изменить через Project Settings из меню File.
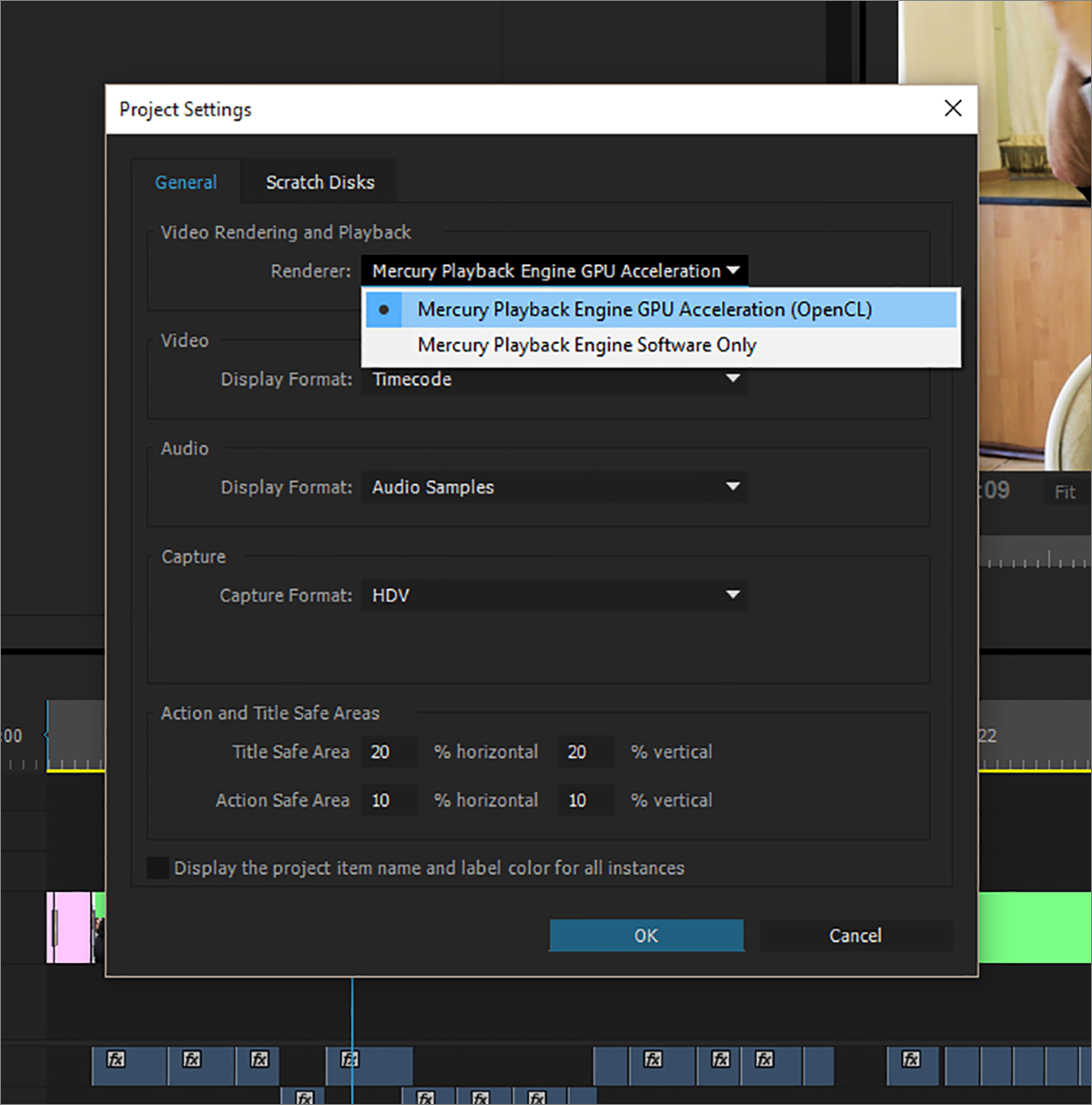
Как я уже говорил, с помощью OpenCL можно переложить на видеокарту вычисления по применению видеоэффектов. Однако не все эффекты в Premiere Pro поддерживают OpenCL – узнать об этом можно по наличию или отсутствию вот такого значка в списке.
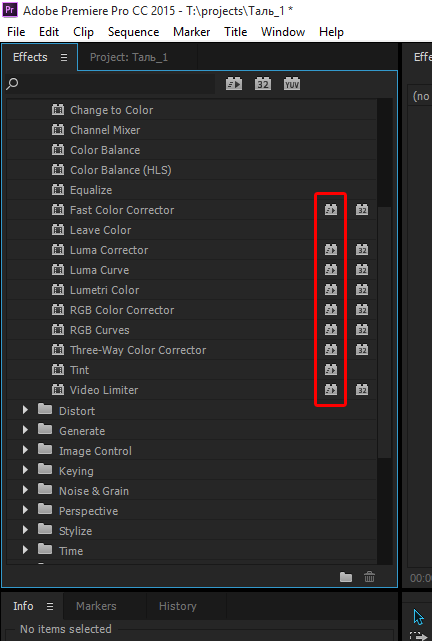
Тесты
В качестве тестового проекта я выбрал двухминутный ролик, состоящий из множества отрезков с видео Full HD с битрейтом 72 Мбит/с и фреймрейтом 24 кадра в секунду. Поверх всего этого безобразия был наложен ускоряемый эффект Lumetri Color, которым я провел цветокорррекцию. На выходе должен был получиться ролик в формате h.264, в разрешении 1920х1080 (то есть без изменений), битрейтом 6-7 Мбит/с, применялась двухпроходное кодирование.
Для подтверждения работы видеокарты я снимал параметры GPU-Z – глядя на частоту графического ядра, легко понять, когда рендеринг видео идет силами центрального процессора, а когда GPU.
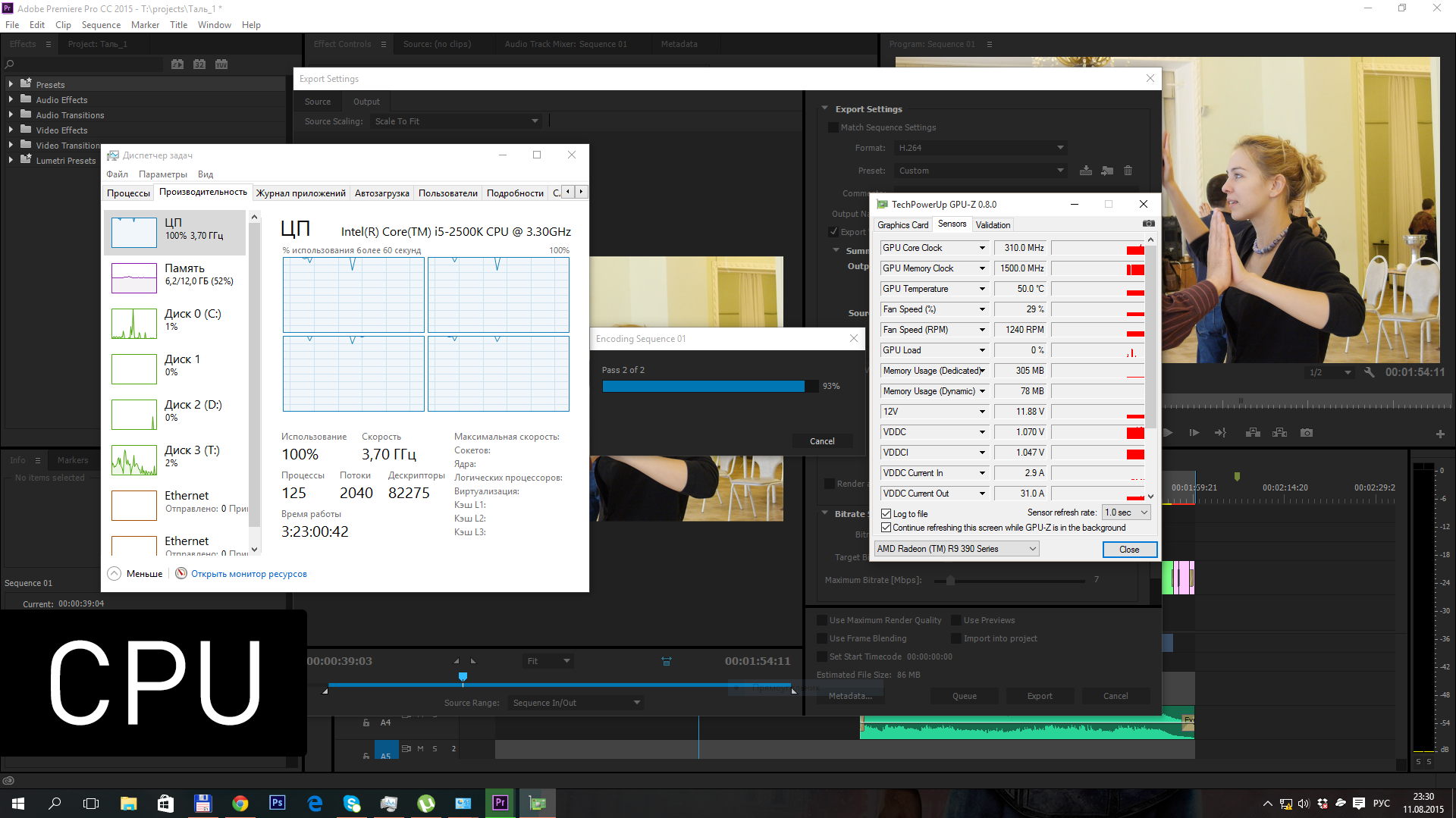
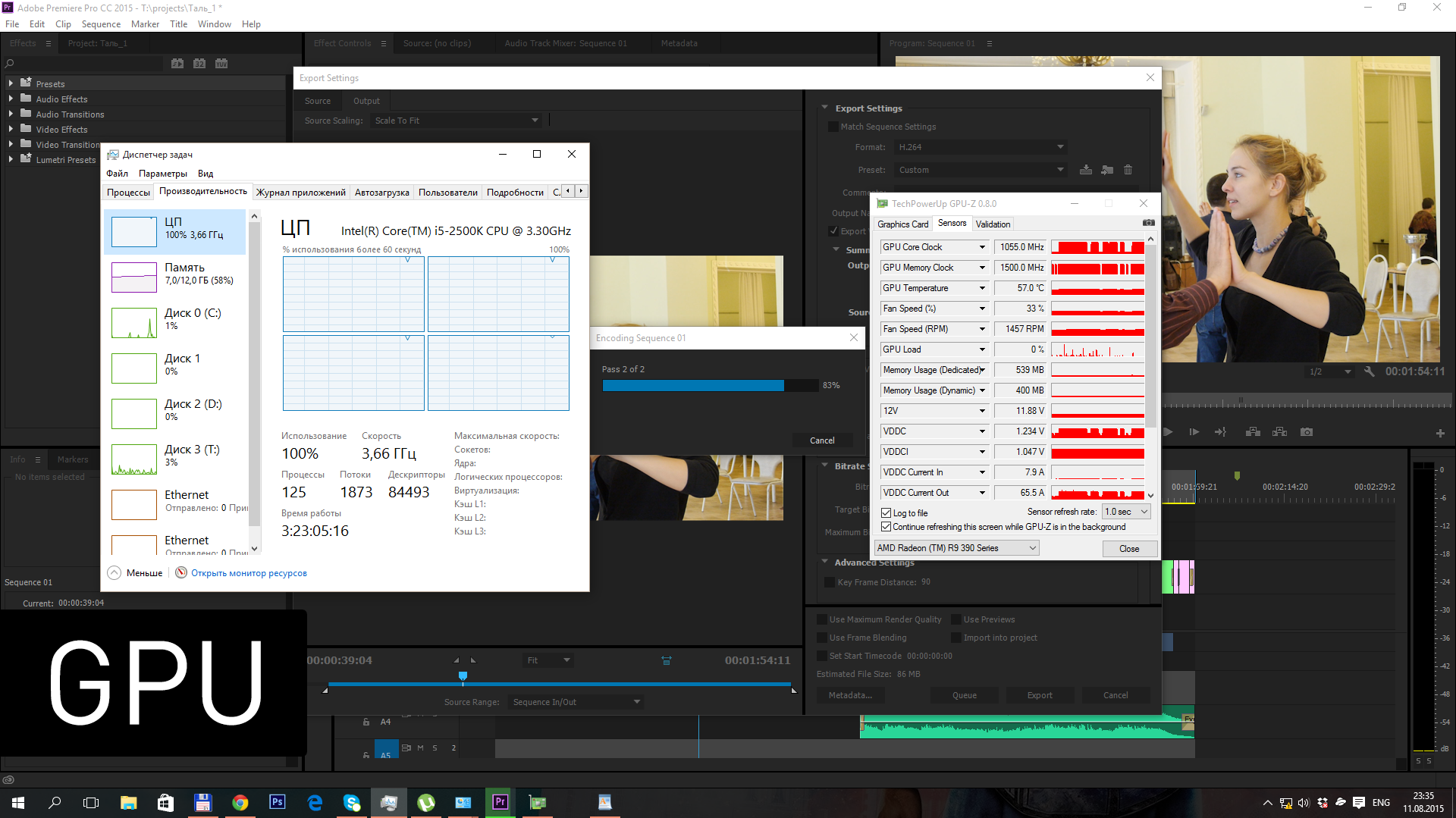
В первом тестовом прогоне я отключил эффект Lumetri Color, так что весь рендеринг заключался в изменении битрейта видео.
Прогон 1:
проект 2 минуты, h.264, 6-7 mbps, без эффектов
| CPU | 3:09 |
| SAPPHIRE Tri-X R9 390X | 2:33 |
| SAPPHIRE NITRO R9 380 | 2:38 |
Без применения эффектов разница в скорости рендеринга между процессором и мощной современной видеокартой очень невелика. При обработке видео общей длительностью около часа выигрыш от использования OpenCL будет более заметным, но все равно очень незначительным. Тем не менее, практически всегда в процессе монтажа к видео применяют эффекты цветокоррекции, поэтому данный тест стоит считать «синтетическим».
Прогон 2:
проект 2 минуты, h.264, 6-7 mbps, эффект Lumetri Color
| CPU | 11:33 |
| SAPPHIRE Tri-X R9 390X | 2:42 |
| SAPPHIRE NITRO R9 380 | 2:48 |
Результаты говорят сами за себя – если обе видеокарты играючи рендерили видео чуть медленнее риалтайма, то процессор на рендеринг каждой минуты тратил почти шесть минут. И это только с одним включенным эффектом! Если перед тестом я рассчитывал в том числе обработать часовой ролик с цветокоррекцией на всей продолжительности, то после полученных результатов от этой идеи решил отказаться. В своей работе я применяю цветокоррекцию для небольших отрезков видео, и час-два рендера меня не сильно напрягают. Терять же четыре-пять часов в тестовых целях мне было некогда.
Экстраполируя результаты, можно считать, что с цветокоррекцией длительностью 60 минут процессор справился бы за 4.5 часа, тогда как видеокартам потребовалось бы менее одного часа!
Выводы
По результатам тестов я оставил себе SAPPHIRE NITRO R9 380 – карта стоит заметно дешевле наикрутейшей R9 390X, но в Premiere Pro производительность двух адаптеров практически идентична. Учитывая, что адаптер покупался для выполнения работы, а значит зарабатывания денег, потраченных 17 тысяч рублей совсем не жалко. Тем более, что и в GTA V карта показала себя молодцом, но это тема совсем для другой заметки.
Что касается опыта применения OpenCL, то нельзя не признать – в мир видеомонтажа пришел спаситель: рендеринг превратился в удовольствие. По сравнению даже с разогнанным Intel Core i5, видеочипы играючи обрабатывают видео с наложенными эффектами в Premiere Pro. При таких результатах тестирования не стоит вопроса, использовать ли рендеринг силами GPU. Вопрос лишь в том, какую видеокарту под это приспособить. Что-нибудь из верхнего игрового сегмента будет в самый раз, например, AMD Radeon R9 3xx. Мои нужды полностью удовлетворил SAPPHIRE NITRO R9 380. Но адаптеры среднего и даже начального уровня также поддерживают OpenCL, а значит заметно ускорят вашу работу в профессиональном софте.


